第06关 K8s资源类型
K8s的API对象(所有怪物角色列表) Namespace – 命令空间实现同一集群上的资源隔离
Pod – K8s的最小运行单元
ReplicaSet – 实现pod平滑迭代更新及回滚用,这个不需要我们实际操作
Deployment – 用来发布无状态应用
Health Check – Readiness/Liveness/maxSurge/maxUnavailable 服务健康状态检测
Service, Endpoint , EndpointSlices – 实现同一lables下的多个pod流量负载均衡
Labels – 标签,服务间选择访问的重要依据
Ingress – K8s的流量入口
DaemonSet – 用来发布守护应用,例如我们部署的CNI插件
HPA – Horizontal Pod Autoscaling 自动水平伸缩
Volume – 存储卷
Pv, pvc, StorageClass – 持久化存储,持久化存储 声明,动态存储pv
StatefulSet – 用来发布有状态应用
Job, CronJob – 一次性任务及定时任务
Configmap, secret – 服务配置及服务加密配置
Kube-proxy – 提供service服务流量转发的功能支持,这个不需要我们实际操作
RBAC, serviceAccount, role, rolebindings, clusterrole, clusterrolebindings – 基于角色的访问控制
Events – K8s事件流,可以用来监控相关事件用,这个不需要我们实际操作
(一)Namespace&Pod
namespace命令空间,后面简称ns。在K8s上面,大部分资源都受ns的限制,来做资源的隔离,少部分如pv,clusterRole等不受ns控制
查询命名空间
# 查看集群上有那些命名空间
# kubectl get ns
NAME STATUS AGE
default Active 8d # 默认命名空间
kube-node-lease Active 8d
kube-public Active 8d
kube-system Active 8d # 系统服务podkubectl使用tab键补全报错问题
https://www.cnblogs.com/albert919/p/16677978.html
https://blog.csdn.net/shileilei1988/article/details/117674615
kubectl ge-bash: _get_comp_words_by_ref: command not foundapt-get install bash-completion
# 有报错就按照提示执行apt --fix-broken install
vi ~/.bashrc 添加source <(kubectl completion bash)
source ~/.bashrc
# 还不行则
source /usr/share/bash-completion/bash_completion创建命名空间
# 创建
# kubectl create ns test
namespace/test created
root@node-1:~# kubectl get ns
NAME STATUS AGE
default Active 9d
kube-node-lease Active 9d
kube-public Active 9d
kube-system Active 9d
test Active 16s
# 删除
root@node-1:~# kubectl delete ns test
namespace "test" deleted查询pod
# 不指定命名空间则使用default
# kubectl get pod
No resources found in default namespace.# 指定系统命名空间pod
>kubectl -n kube-system get pod
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-67c67b9b5f-t69q6 1/1 Running 1 (107m ago) 8d
calico-node-4x4g8 1/1 Running 2 (179m ago) 9d
calico-node-k2kw6 1/1 Running 3 (107m ago) 9d
calico-node-kd2hj 1/1 Running 3 (107m ago) 9d
coredns-65bc7b648d-92n9q 1/1 Running 1 (107m ago) 8d
metrics-server-56774d6954-nk6j4 1/1 Running 3 (105m ago) 8d
node-local-dns-9p4pd 1/1 Running 3 (107m ago) 9d
node-local-dns-kcdtq 1/1 Running 2 (179m ago) 9d
node-local-dns-rfwkm 1/1 Running 3 (107m ago) 9d
- Pending(等待):Pod已经被创建,但是尚未被调度到某个节点上运行。
- Running(运行中):Pod已经被调度到节点上,并且至少有一个容器在运行。
- Succeeded(成功):Pod中的所有容器已经成功地执行完任务,并且不再运行。
- Failed(失败):Pod中的所有容器至少有一个处于失败状态。
- Unknown(未知):Pod的状态无法被获取。这可能是因为调度器无法与Pod通信。
Kubernetes中的"CrashLoopBackOff"是指一个Pod中的某个容器处于不断崩溃并重启的状态。这通常是由于容器中的应用程序遇到了错误或者异常,导致容器无法正常运行。当一个容器不断崩溃并重启时,Kubernetes会将Pod的状态设置为"CrashLoopBackOff",并尝试在一段时间后重新启动容器,以期望应用程序能够恢复正常运行。
创建pod
创建一个nginx的pod,用全称
# kubectl run nginx --image=docker.io/library/nginx:1.21.6
pod/nginx created
>kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 0/1 ContainerCreating 0 2m22s <none> 10.0.1.203 <none> <none>
# 处于ContainerCreating,全部重启后自动好了
>curl 172.20.139.81
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
</head>
<body>
<h1>Welcome to nginx!</h1>
</body>
</html>kubectl config view进入pod
# 进入pod
>kubectl exec -it nginx -- bash
root@nginx:/#
# 修改文件
# echo 'hello, world!' > /usr/share/nginx/html/index.html
# exit
# curl 172.20.139.81
hello, world!查看pod详细信息
# 查看pod详细信息
# Node:节点 Events:事件
# default-scheduler调度组件 kubelet:k8s客户端
>kubectl -n default describe pod nginx
Name: nginx
Namespace: default
Priority: 0
Service Account: default
Node: 10.0.1.203/10.0.1.203
Start Time: Wed, 01 May 2024 00:11:39 +0800
Labels: run=nginx
Annotations: <none>
Status: Running
IP: 172.20.139.81
IPs:
IP: 172.20.139.81
Containers:
nginx:
Container ID: containerd://9bf12b966a8337e80cf5527ecde81d6035d75e4fe297fdd7373a6a2aa412f915
Image: docker.io/library/nginx:1.21.6
Image ID: docker.io/library/nginx@sha256:2bcabc23b45489fb0885d69a06ba1d648aeda973fae7bb981bafbb884165e514
Port: <none>
Host Port: <none>
State: Running
Started: Wed, 01 May 2024 01:00:36 +0800
Last State: Terminated
Reason: Unknown
Exit Code: 255
Started: Wed, 01 May 2024 00:34:05 +0800
Finished: Wed, 01 May 2024 01:00:19 +0800
Ready: True
Restart Count: 2
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-8m244 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-8m244:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 67m default-scheduler Successfully assigned default/nginx to 10.0.1.203
Normal Pulling 67m kubelet Pulling image "docker.io/library/nginx:1.21.6"
Normal Pulled 50m kubelet Successfully pulled image "docker.io/library/nginx:1.21.6" in 17m21.534769723s (17m21.534838763s including waiting)
Normal Created 50m kubelet Created container nginx
Normal Started 50m kubelet Started container nginx
Warning NodeNotReady 45m node-controller Node is not ready
Normal SandboxChanged 45m kubelet Pod sandbox changed, it will be killed and re-created.
Normal Pulled 45m kubelet Container image "docker.io/library/nginx:1.21.6" already present on machine
Normal Created 45m kubelet Created container nginx
Normal Started 45m kubelet Started container nginx
Warning NodeNotReady 19m node-controller Node is not ready
Normal SandboxChanged 18m kubelet Pod sandbox changed, it will be killed and re-created.
Normal Pulled 18m kubelet Container image "docker.io/library/nginx:1.21.6" already present on machine
Normal Created 18m kubelet Created container nginx
Normal Started 18m kubelet Started container nginx删除pod
# 我们删除掉这个nginx的pod
# kubectl delete pod nginx
pod "nginx" deleted
# kubectl get pod
现在已经看不到这个pod了,假设这里是我们运行的一个服务,而恰好运行这个pod的这台node当机了,那么这个服务就没了,它不会自动飘移到其他node上去,也就发挥不了K8s最重要的保持期待服务运行数量的服务特性了。# 创建一个redis服务的pod
>kubectl run redis --image=docker.io/library/redis:latest
# 使用exec进入这个pod,
>kubectl exec -it redis -- bash
# 通过客户端命令redis-cli连接到redis-server ,
root@redis:/data# redis-cli
# 插入一个key a ,value 为666
127.0.0.1:6379> get a
(nil)
127.0.0.1:6379> set a 666
OK
127.0.0.1:6379> get a
"666"
# 最后删除这个redis的pod
127.0.0.1:6379> exit
root@redis:/data# exit
exit
>kubectl delete pod redis
pod "redis" deleted
>kubectl get pod
No resources found in default namespace.查看集群状态
# 查看集群状态
> kubecti get node
NAME STATUS ROLES AGE VERSION
10.0.1.201 Ready,SchedulingDisabled master 9d v1.27.5
10.0.1.202 Ready,SchedulingDisabled master 9d v1.27.5
10.0.1.203 Ready node 9d v1.27.5强制删除namespaces
生产中的小技巧:k8s删除namespaces状态一直为terminating问题处理
# kubectl get ns
NAME STATUS AGE
default Active 5d4h
ingress-nginx Active 30h
kube-node-lease Active 5d4h
kube-public Active 5d4h
kube-system Active 5d4h
kubevirt Terminating 2d2h # <------ here
1、新开一个窗口运行命令 kubectl proxy
> 此命令启动了一个代理服务来接收来自你本机的HTTP连接并转发至API服务器,同时处理身份认证
2、新开一个终端窗口,将下面shell脚本整理到文本内`1.sh`并执行,$1参数即为删除不了的ns名称
#------------------------------------------------------------------------------------
#!/bin/bash
set -eo pipefail
die() { echo "$*" 1>&2 ; exit 1; }
need() {
which "$1" &>/dev/null || die "Binary '$1' is missing but required"
}
# checking pre-reqs
need "jq"
need "curl"
need "kubectl"
PROJECT="$1"
shift
test -n "$PROJECT" || die "Missing arguments: kill-ns <namespace>"
kubectl proxy &>/dev/null &
PROXY_PID=$!
killproxy () {
kill $PROXY_PID
}
trap killproxy EXIT
sleep 1 # give the proxy a second
kubectl get namespace "$PROJECT" -o json | jq 'del(.spec.finalizers[] | select("kubernetes"))' | curl -s -k -H "Content-Type: application/json" -X PUT -o /dev/null --data-binary @- http://localhost:8001/api/v1/namespaces/$PROJECT/finalize && echo "Killed namespace: $PROJECT"
#------------------------------------------------------------------------------------
3. 执行脚本删除
# bash 1.sh kubevirt
Killed namespace: kubevirt
1.sh: line 23: kill: (9098) - No such process
5、查看结果
# kubectl get ns
NAME STATUS AGE
default Active 5d4h
ingress-nginx Active 30h
kube-node-lease Active 5d4h
kube-public Active 5d4h
kube-system Active 5d4h(二)Deployment
K8s会通过各种Controller来管理Pod的生命周期,为了满足不同的业务场景,K8s开发了Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job、cronJob等多种Controller ,这里我们首先来学习下最常用的Deployment,这是我们生产中用的最多的一个controller,适合用来发布无状态应用。
# 创建一个deployment,引用nginx的服务镜像,这里的副本数量默认是1,nginx容器镜像用的是latest
# 在K8s新版本开始,对服务api进行了比较大的梳理,明确了各个api的具体职责,而不像以前旧版本那样混为一谈
# 创建deployment
> kubectl create deployment nginx --image=docker.io/library/nginx:1.21.6
deployment.apps/nginx created
# 查询
> kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 24s
# 查看自动关联创建的副本集(replicaset)
> kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-796b85dbb8 1 1 1 41s
# 查看pod
> kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-796b85dbb8-p8gq2 1/1 Running 0 5m10s# 扩容pod
> kubectl scale deployment nginx --replicas=2
deployment.apps/nginx scaled
# 查看pod
> kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-796b85dbb8-dz2l4 1/1 Running 0 15s 172.20.139.88 10.0.1.203 <none> <none>
nginx-796b85dbb8-p8gq2 1/1 Running 0 13m 172.20.139.87 10.0.1.203 <none> <none># 创建service 加--dry-run=client参数不会真的创建,只输出配置
> kubectl create service clusterip nginx --tcp=80:80 --dry-run=client -o yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: nginx
name: nginx
spec:
ports:
- name: 80-80
port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx
type: ClusterIP
status:
loadBalancer: {}
# 创建service
> kubectl create service clusterip nginx --tcp=80:80
service/nginx created
# 查看
> kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 9d <none>
nginx ClusterIP 10.68.163.5 <none> 80/TCP 40s app=nginx
> kubectl get pod -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-796b85dbb8-dz2l4 1/1 Running 0 4h29m
nginx-796b85dbb8-p8gq2 1/1 Running 0 4h42m轮询
# 测试轮询
> kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-796b85dbb8-dz2l4 1/1 Running 0 4h34m 172.20.139.88 10.0.1.203 <none> <none>
nginx-796b85dbb8-p8gq2 1/1 Running 0 4h47m 172.20.139.87 10.0.1.203 <none> <none>
# 进入
> kubectl exec -it nginx-796b85dbb8-dz2l4 -- bash
# 修改文件
root@nginx-796b85dbb8-dz2l4:/# echo nginx-796b85dbb8-dz2l4 > /usr/share/nginx/html/index.html
root@nginx-796b85dbb8-dz2l4:/# exit
exit
command terminated with exit code 127
> kubectl exec -it nginx-796b85dbb8-p8gq2 -- bash
root@nginx-796b85dbb8-p8gq2:/# echo nginx-796b85dbb8-p8gq2 > /usr/share/nginx/html/index.html
root@nginx-796b85dbb8-p8gq2:/# exit
exit
# 请求测试
root@node-1:~# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 9d <none>
nginx ClusterIP 10.68.163.5 <none> 80/TCP 16m app=nginx
root@node-1:~# curl 10.68.163.5
nginx-796b85dbb8-dz2l4
root@node-1:~# curl 10.68.163.5
nginx-796b85dbb8-p8gq2
root@node-1:~# curl 10.68.163.5
nginx-796b85dbb8-dz2l4# 查看版本
> nginx_svc=$(kubectl get svc --no-headers |awk '/^nginx/{print $3}')
> curl ${nginx_svc}/1
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.21.6</center>
</body>
</html>
# 根据输出可以看到版本号是nginx/1.21.6,我们这里模拟服务发版操作,先来看下有哪些版本的nginx
> ctr -n k8s.io images ls|grep nginx
# 注意命令最后面的 `--record` 参数,这个在生产中作为资源创建更新用来回滚的重要标记,强烈建议在生产中操作时都加上这个参数
> kubectl set image deployment/nginx nginx=docker.io/library/nginx:1.25.1 --record
deployment.apps/nginx image updated
# 观察下pod的信息,可以看到旧nginx的2个pod逐渐被新的pod一个一个的替换掉
# kubectl get pod -w
NAME READY STATUS RESTARTS AGE
nginx-5f5f7c68bc-csgw2 1/1 Running 0 2m18s
nginx-5f5f7c68bc-gbkl9 0/1 ContainerCreating 0 84s
nginx-796b85dbb8-hrlrx 1/1 Running 0 12m
# 我们再看下nginx的rs,可以看到现在有两个了
# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-5f5f7c68bc 2 2 2 5m7s
nginx-796b85dbb8 0 0 0 16m
# 看下现在nginx的描述信息,我们来详细分析下这个过程
# kubectl describe deployments.apps nginx# 升级nginx的版本
# kubectl set image deployments/nginx nginx=docker.io/library/nginx:1.21.6 --record
# 查看pod
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-796b85dbb8-n65l9 1/1 Running 0 17s 172.20.139.112 10.0.1.203 <none> <none>
nginx-796b85dbb8-pz85g 1/1 Running 0 19s 172.20.139.111 10.0.1.203 <none> <none>
# 这里假设是我们在发版服务的新版本,结果线上反馈版本有问题,需要马上回滚,看看在K8s上怎么操作吧
# 首先通过命令查看当前历史版本情况,只有接了`--record`参数的命令操作才会有详细的记录,这就是为什么在生产中操作一定得加上的原因了
# kubectl rollout history deployment nginx
deployment.apps/nginx
REVISION CHANGE-CAUSE
2 kubectl set image deployment/nginx nginx=docker.io/library/nginx:1.25.1 --record=true
3 kubectl set image deployments/nginx nginx=docker.io/library/nginx:1.21.6 --record=true
# 回滚
# 根据历史发布版本前面的阿拉伯数字序号来选择回滚版本,这里我们回到上个版本号,也就是选择2 ,执行命令如下:
# kubectl rollout undo deployment nginx --to-revision=2
deployment.apps/nginx rolled back
# 查看pod
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-5f5f7c68bc-97pf6 1/1 Running 0 4s 172.20.139.114 10.0.1.203 <none> <none>
nginx-5f5f7c68bc-wt9kp 1/1 Running 0 5s 172.20.139.113 10.0.1.203 <none> <none>
# curl 172.20.139.113/1
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.25.1</center>
</body>
</html>| tail -2
tail是一个命令行工具,用于显示文件的末尾内容。-1表示显示文件末尾的最后一行,而-2表示显示文件末尾的最后两行
# 查看deployment
# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 2/2 2 2 4d3h
# 删除deployment
# kubectl -n default delete deployment nginx
deployment.apps "nginx" deleted
# 检查
# kubectl get deployments.apps
No resources found in default namespace.
# kubectl get pod
No resources found in default namespace.
# kubectl get rs
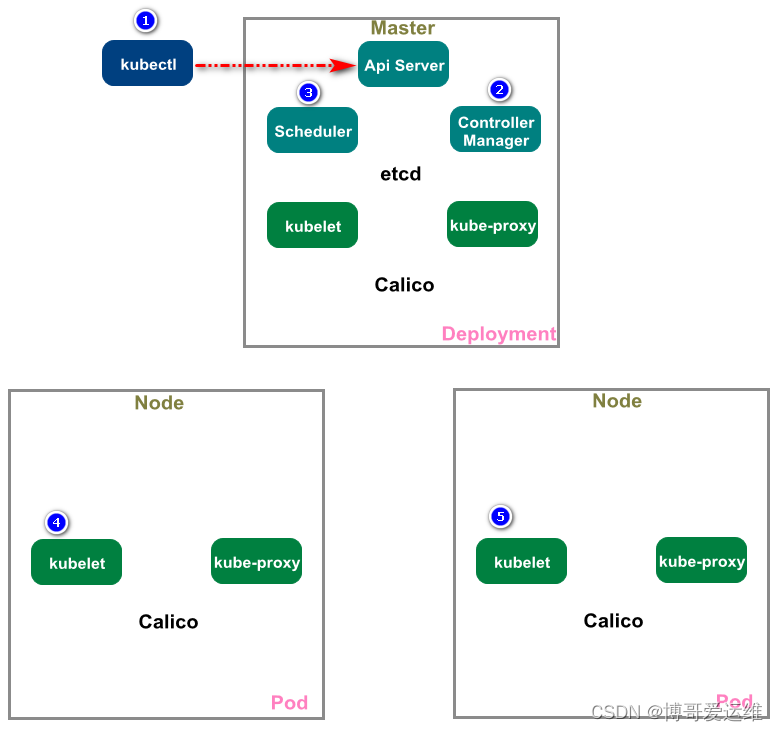
No resources found in default namespace.Deployment很重要,我们这里再来回顾下整个部署过程,加深理解
 10.0.1.203 ------------------------------------------------------------------------------------- 10.0.1.204
10.0.1.203 ------------------------------------------------------------------------------------- 10.0.1.204
- kubectl 发送部署请求到 API Server
- API Server 通知 Controller Manager 创建一个 deployment 资源(scale扩容)
- Scheduler 执行调度任务,将两个副本 Pod 分发到 10.0.1.203 和 10.0.1.204
- 10.0.1.203 和 10.0.1.204 上的 kubelet在各自的节点上创建并运行 Pod
- 升级deployment的nginx服务镜像
这里补充一下:
这些应用的配置和当前服务的状态信息都是保存在ETCD中,执行kubectl get pod等操作时API Server会从ETCD中读取这些数据
calico会为每个pod分配一个ip,但要注意这个ip不是固定的,它会随着pod的重启而发生变化
附:Node管理
禁止pod调度到该节点上
kubectl cordon <node name> --delete-emptydir-data --ignore-daemonsets驱逐该节点上的所有pod
kubectl drain <node name>该命令会删除该节点上的所有Pod(DaemonSet除外),在其他node上重新启动它们,通常该节点需要维护时使用该命令。直接使用该命令会自动调用kubectl cordon <node>命令。当该节点维护完成,启动了kubelet后,再使用kubectl uncordon <node>即可将该节点添加到kubernetes集群中。
上面我们是用命令行来创建的deployment,但在生产中,很多时候,我们是直接写好yaml配置文件,再通过kubectl apply -f xxx.yaml来创建这个服务,我们现在用yaml配置文件的方式实现上面deployment服务的创建
需要注意的是,yaml文件格式缩进和python语法类似,对于缩进格式要求很严格,任何一处错误,都会造成无法创建,这里教大家一招实用的技巧来生成规范的yaml配置
# 这条命令是不是很眼熟,对了,这就是上面创建deployment的命令,我们在后面加上`--dry-run -o yaml`,--dry-run代表这条命令不会实际在K8s执行,-o yaml是会将试运行结果以yaml的格式打印出来,这样我们就能轻松获得yaml配置了
# kubectl create deployment nginx --image=nginx --dry-run -o yaml
apiVersion: apps/v1 # <--- apiVersion 是当前配置格式的版本
kind: Deployment #<--- kind 是要创建的资源类型,这里是 Deployment
metadata: #<--- metadata 是该资源的元数据,name 是必需的元数据项
creationTimestamp: null
labels:
app: nginx
name: nginx
spec: #<--- spec 部分是该 Deployment 的规格说明
replicas: 1 #<--- replicas 指明副本数量,默认为 1
selector:
matchLabels:
app: nginx
strategy: {}
template: #<--- template 定义 Pod 的模板,这是配置文件的重要部分
metadata: #<--- metadata 定义 Pod 的元数据,至少要定义一个 label。label 的 key 和 value 可以任意指定
creationTimestamp: null
labels:
app: nginx
spec: #<--- spec 描述 Pod 的规格,此部分定义 Pod 中每一个容器的属性,name 和 image 是必需的
containers:
- image: nginx
name: nginx
resources: {}
status: {}我们这里用这个yaml文件来创建nginx的deployment试试,我们先删除掉先用命令行创建的nginx
# 在K8s上命令行删除一个资源直接用delete参数
# kubectl delete deployment nginx
deployment.apps "nginx" deleted
# 可以看到关联的rs副本集也被自动清空了
# kubectl get rs
No resources found in default namespace.
# 相关的pod也没了
# kubectl get pod
No resources found in default namespace.生成nginx.yaml文件
# kubectl create deployment nginx --image=nginx --dry-run -o yaml > nginx.yaml
我们注意到执行上面命令时会有一条告警提示... --dry-run is deprecated and can be replaced with --dry-run=client. ,虽然并不影响我们生成正常的yaml配置,但如果看着不爽可以按命令提示将--dry-run换成--dry-run=client
# 接着我们vim nginx.yaml,将replicas: 1的数量改成replicas: 2
# 开始创建,我们后面这类基于yaml文件来创建资源的命令统一都用apply了
# kubectl apply -f nginx.yaml
deployment.apps/nginx created
# 查看创建的资源,这个有个小技巧,同时查看多个资源可以用,分隔,这样一条命令就可以查看多个资源了
# kubectl get deployment,rs,pod
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx 2/2 2 2 116s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-f89759699 2 2 2 116s
NAME READY STATUS RESTARTS AGE
pod/nginx-f89759699-bzwd2 1/1 Running 0 116s
pod/nginx-f89759699-qlc8q 1/1 Running 0 116snginx生产进阶yaml配置
nginx.yaml
---
kind: Service
apiVersion: v1
metadata:
name: new-nginx
spec:
selector:
app: new-nginx
ports:
- name: http-port
port: 80
protocol: TCP
targetPort: 80
---
# 新版本k8s的ingress配置
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: new-nginx
annotations:
nginx.ingress.kubernetes.io/force-ssl-redirect: "true"
nginx.ingress.kubernetes.io/whitelist-source-range: 0.0.0.0/0
nginx.ingress.kubernetes.io/configuration-snippet: |
if ($host != 'www.boge.com' ) {
rewrite ^ http://www.boge.com$request_uri permanent;
}
spec:
rules:
- host: boge.com
http:
paths:
- backend:
service:
name: new-nginx
port:
number: 80
path: /
pathType: Prefix
- host: m.boge.com
http:
paths:
- backend:
service:
name: new-nginx
port:
number: 80
path: /
pathType: Prefix
- host: www.boge.com
http:
paths:
- backend:
service:
name: new-nginx
port:
number: 80
path: /
pathType: Prefix
# tls:
# - hosts:
# - boge.com
# - m.boge.com
# - www.boge.com
# secretName: boge-com-tls
# kubectl -n <namespace> create secret tls boge-com-tls --key boge.key --cert boge.csr
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: new-nginx
labels:
app: new-nginx
spec:
replicas: 2
selector:
matchLabels:
app: new-nginx
template:
metadata:
labels:
app: new-nginx
spec:
containers:
#--------------------------------------------------
- name: new-nginx
image: nginx:1.21.6
# image: nginx:1.25.1
env:
- name: TZ
value: Asia/Shanghai
ports:
- containerPort: 80
volumeMounts:
- name: html-files
mountPath: "/usr/share/nginx/html"
#--------------------------------------------------
- name: busybox
image: registry.cn-shanghai.aliyuncs.com/acs/busybox:v1.29.2
# image: nicolaka/netshoot
args:
- /bin/sh
- -c
- >
while :; do
if [ -f /html/index.html ];then
echo "[$(date +%F\ %T)] ${MY_POD_NAMESPACE}-${MY_POD_NAME}-${MY_POD_IP}" > /html/index.html
sleep 1
else
touch /html/index.html
fi
done
env:
- name: TZ
value: Asia/Shanghai
- name: MY_POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: MY_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
volumeMounts:
- name: html-files
mountPath: "/html"
- mountPath: /etc/localtime
name: tz-config
#--------------------------------------------------
volumes:
- name: html-files
emptyDir:
medium: Memory
sizeLimit: 10Mi
- name: tz-config
hostPath:
path: /usr/share/zoneinfo/Asia/ShanghaiYAML流中的文档通常是通过三个连字符(---)分隔开来的
volumes和containers同级
这段配置是用于Kubernetes集群中部署和管理一个简单的Web服务的YAML文件,包含了Service、Ingress和Deployment资源定义。下面是对各部分的详细解释:
Service (new-nginx)
- Kind: Service
- API Version: v1
定义了一个名为new-nginx的Service,它选择具有标签app: new-nginx的Pod作为后端,并且在端口80上暴露HTTP服务。这个Service使得Pod可以通过一个稳定的内部IP地址和端口访问,不论后端Pod如何变化。
Ingress (new-nginx)
- API Version: networking.k8s.io/v1
定义了一个Ingress资源,同样命名为new-nginx,用于管理进入集群的HTTP(S)流量。配置包括:
- 强制HTTPS重定向。
- 指定了允许访问的源IP范围为所有(示例配置,实际生产环境应限制为安全的IP范围)。
- 添加了一个Nginx配置片段,用于将非
www.boge.com的主机请求重定向到www.boge.com。 - 配置了三条路由规则,分别针对
boge.com、m.boge.com和www.boge.com,都将请求路由到new-nginxService的80端口。注释掉了TLS部分,实际部署时可根据需要启用以支持HTTPS。
Deployment (new-nginx)
- Kind: Deployment
- API Version: apps/v1
创建了一个名为new-nginx的Deployment,用于管理一组运行着Nginx的Pod实例。具体配置如下:
- 设置副本数为2,确保有至少两个Pod运行,实现高可用性。
- 使用标签选择器匹配标签
app: new-nginx的Pod。 - Pod模板中定义了两个容器:
- new-nginx Container:使用Nginx镜像(版本1.21.6),环境变量设置时区为亚洲/上海,端口映射80,挂载一个内存中的空目录到
/usr/share/nginx/html以便存储静态文件。 - busybox Container:使用BusyBox镜像,执行一个脚本定期更新
/html/index.html文件内容,显示Pod的名称、命名空间和IP地址,同样设置了时区并挂载了时区配置和上述的HTML文件目录。
- new-nginx Container:使用Nginx镜像(版本1.21.6),环境变量设置时区为亚洲/上海,端口映射80,挂载一个内存中的空目录到
此外,还定义了两个卷(html-files 和 tz-config)用于存储动态生成的HTML文件和时区配置。
综上所述,此配置文件旨在部署一个Nginx服务,通过Ingress进行流量管理和路由,同时使用Deployment确保服务的稳定性和可扩展性,以及通过BusyBox容器动态展示Pod信息。
部署
# 删除service
# kubectl -n default delete svc nginx
service "nginx" deleted
# 使用yaml文件启动
# kubectl -n default apply -f nginx.yaml
service/new-nginx created
ingress.networking.k8s.io/new-nginx created
deployment.apps/new-nginx created
# 查看service
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 13d
new-nginx ClusterIP 10.68.9.59 <none> 80/TCP 46s
# 查看pod
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
new-nginx-854cf59647-qxljk 2/2 Running 0 99s 172.20.139.116 10.0.1.203 <none> <none>
new-nginx-854cf59647-wdrnd 2/2 Running 0 99s 172.20.139.115 10.0.1.203 <none> <none>
# 轮询请求
# curl 10.68.9.59
default-new-nginx-854cf59647-wdrnd-172.20.139.115
# curl 10.68.9.59
default-new-nginx-854cf59647-qxljk-172.20.139.116vi gg回到第一行
基于这两种资源创建的方式作个总结:
基于命令的方式:
1.简单直观快捷,上手快。
2.适合临时测试或实验。
基于配置文件的方式:
1.配置文件详细描述了服务的所有需求,即应用最终要达到的状态。
2.配置文件提供了创建资源的模板,能够重复部署。
3.可以像管理代码一样管理部署。
4.适合正式的、跨环境的、规模化部署。
5.这种方式要求熟悉配置文件的语法,有一定难度。练习
试着用命令行和yaml配置这两种方式,来创建redis的deployment服务,同时可以将pod后面的作业再复习下
# 命令
# kubectl create deployment redis --image=docker.io/library/redis:latest
deployment.apps/redis created
# kubectl get pod
NAME READY STATUS RESTARTS AGE
new-nginx-854cf59647-qxljk 2/2 Running 0 51m
new-nginx-854cf59647-wdrnd 2/2 Running 0 51m
redis-64555b755d-62w6v 1/1 Running 0 97s# 创建yaml文件
# kubectl create deployment redis --image=docker.io/library/redis:latest --dry-run=client -o yaml > redis.yaml
# 编辑nginx.yaml,将replicas: 1的数量改成replicas: 2
# 创建deployment
# kubectl -n default apply -f redis.yaml
# 查看创建的资源
# kubectl get deployment,rs,pod
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/new-nginx 2/2 2 2 78m
deployment.apps/redis 2/2 2 2 34s
NAME DESIRED CURRENT READY AGE
replicaset.apps/new-nginx-854cf59647 2 2 2 78m
replicaset.apps/redis-64555b755d 2 2 2 34s
NAME READY STATUS RESTARTS AGE
pod/new-nginx-854cf59647-qxljk 2/2 Running 0 78m
pod/new-nginx-854cf59647-wdrnd 2/2 Running 0 78m
pod/redis-64555b755d-jm7fm 1/1 Running 0 34s
pod/redis-64555b755d-n88d9 1/1 Running 0 34s(三)健康
在K8s上,强大的自愈能力是这个容器编排引擎的非常重要的一个特性,自愈的默认实现方式是通过自动重启发生故障的容器,使之恢复正常。除此之外,我们还可以利用Liveness 和 Readiness检测机制来设置更为精细的健康检测指标,从而实现如下的需求:
- 零停机部署
- 避免部署无效的服务镜像
- 更加安全的滚动升级
下面我们先来实践学习下K8s的Healthz Check功能,我们先来学习下K8s默认的健康检测机制:
每个容器启动时都会执行一个进程,此进程是由Dockerfile的CMD 或 ENTRYPOINT来指定,当容器内进程退出时返回状态码为非零,则会认为容器发生了故障,K8s就会根据restartPolicy来重启这个容器,以达到自愈的效果。
模拟一个容器发生故障时的场景 :
# 先来生成一个pod的yaml配置文件,并对其进行相应修改
# kubectl run busybox --image=busybox --dry-run=client -o yaml > testHealthz.yaml
# vim testHealthz.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: busybox
name: busybox
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
name: busybox
resources: {}
args:
- /bin/sh
- -c
- sleep 10; exit 1 # 并添加pod运行指定脚本命令,模拟容器启动10秒后发生故障,退出状态码为1
dnsPolicy: ClusterFirst
restartPolicy: OnFailure # 将默认的Always修改为OnFailure
status: {}| 重启策略 | 说明 |
|---|---|
| Always | 当容器失效时,由kubelet自动重启该容器 |
| OnFailure | 当容器终止运行且退出码不为0时,由kubelet自动重启该容器 |
| Never | 不论容器运行状态如何,kubelet都不会重启该容器 |
执行配置创建pod
# kubectl apply -f testHealthz.yaml
pod/busybox created
# 观察几分钟,利用-w 参数来持续监听pod的状态变化
# kubectl get pod -w
NAME READY STATUS RESTARTS AGE
busybox 0/1 ContainerCreating 0 4s
busybox 1/1 Running 0 6s
busybox 0/1 Error 0 16s上面可以看到这个测试pod被重启了5次,然而服务始终正常不了,就会保持在CrashLoopBackOff了,等待运维人员来进行下一步错误排查
注:kubelet会以指数级的退避延迟(10s,20s,40s等)重新启动它们,上限为5分钟
这里我们是人为模拟服务故障来进行的测试,在实际生产工作中,对于业务服务,我们如何利用这种重启容器来恢复的机制来配置业务服务呢,答案是liveness检测
# 删除
# kubectl delete -f testHealthz.yaml
pod "busybox" deletedLiveness
Liveness检测让我们可以自定义条件来判断容器是否健康,如果检测失败,则K8s会重启容器,我们来个例子实践下,准备如下yaml配置并保存为liveness.yaml:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness
spec:
restartPolicy: OnFailure
containers:
- name: liveness
image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10 # 容器启动 10 秒之后开始检测
periodSeconds: 5 # 每隔 5 秒再检测一次启动进程首先创建文件 /tmp/healthy,30 秒后删除,
livenessProbe 部分定义如何执行 Liveness 检测:
检测的方法是:通过 cat 命令检查 /tmp/healthy 文件是否存在。
如果命令执行成功,返回值为零,K8s 则认为本次 Liveness 检测成功;如果命令返回值非零,本次 Liveness 检测失败。
initialDelaySeconds: 10 。指定容器启动 10 之后开始执行 Liveness 检测,我们一般会根据应用启动的准备时间来设置。比如某个应用正常启动要花 30 秒,那么 initialDelaySeconds 的值就应该大于 30。
periodSeconds: 5 。指定每 5 秒执行一次 Liveness 检测。K8s 如果连续执行 3 次 Liveness 检测均失败,则会杀掉并重启容器。
# 创建这个Pod:
# kubectl apply -f liveness.yaml
pod/liveness created从配置文件可知,最开始的 30 秒,/tmp/healthy 存在,cat 命令返回 0,Liveness 检测成功,这段时间 kubectl describe pod liveness 的 Events部分会显示正常的日志
35 秒之后,日志会显示 /tmp/healthy 已经不存在,Liveness 检测失败。再过几十秒,几次检测都失败后,容器会被重启。
Readiness
我们可以通过Readiness检测来告诉K8s什么时候可以将pod加入到服务Service的负载均衡池中,对外提供服务,这个在生产场景服务发布新版本时非常重要,当我们上线的新版本发生程序错误时,Readiness会通过检测发布,从而不导入流量到pod内,将服务的故障控制在内部,在生产场景中,建议这个是必加的,Liveness不加都可以,因为有时候我们需要保留服务出错的现场来查询日志,定位问题,告之开发来修复程序。
Readiness 检测的配置语法与 Liveness 检测完全一样,下面是个例子:
apiVersion: v1
kind: Pod
metadata:
labels:
test: readiness
name: readiness
spec:
restartPolicy: OnFailure
containers:
- name: readiness
image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
readinessProbe: # 这里将livenessProbe换成readinessProbe即可,其它配置都一样
exec:
command:
- cat
- /tmp/healthy
#initialDelaySeconds: 10 # 容器启动 10 秒之后开始检测
periodSeconds: 5 # 每隔 5 秒再检测一次
startupProbe: # 启动探针,更灵活,完美代替initialDelaySeconds强制等待时间配置,启动时每3秒检测一次,一共检测100次
exec:
command:
- cat
- /tmp/healthy
failureThreshold: 100
periodSeconds: 3
timeoutSeconds: 1# 启动pod
# kubectl apply -f readiness.yaml
pod/readiness created
# 跟踪pod状态
# kubectl get pod -w
NAME READY STATUS RESTARTS AGE
readiness 0/1 Running 0 2s
readiness 0/1 Running 0 4s
readiness 1/1 Running 0 5s
readiness 0/1 Running 0 46s
readiness 0/1 Completed 0 10m然后35秒后,文件被删除,这个时候READY状态就会发生变化,K8s会断开Service到pod的流量
READY(0/1) 可以看到pod的流量被断开,这时候即使服务出错,对外界来说也是感知不到的,这时候我们运维人员就可以进行故障排查了
kubectl describe pod readinessLiveness和 Readiness 比较
Liveness 检测和 Readiness 检测是两种 Health Check 机制,如果不特意配置,Kubernetes 将对两种检测采取相同的默认行为,即通过判断容器启动进程的返回值是否为零来判断检测是否成功。
两种检测的配置方法完全一样,支持的配置参数也一样。不同之处在于检测失败后的行为:Liveness 检测是重启容器;Readiness 检测则是将容器设置为不可用,不接收 Service 转发的请求。
Liveness 检测和 Readiness 检测是独立执行的,二者之间没有依赖,所以可以单独使用,也可以同时使用。用 Liveness 检测判断容器是否需要重启以实现自愈;用 Readiness 检测判断容器是否已经准备好对外提供服务。
Liveness 和 Readiness 的三种使用方式
readinessProbe: # 定义只有http检测容器6222端口请求返回是 200-400,则接收下面的Service web-svc 的请求
httpGet:
scheme: HTTP
path: /check
port: 6222
initialDelaySeconds: 10 # 容器启动 10 秒之后开始探测,注意观察下g1的启动成功时间
periodSeconds: 5 # 每隔 5 秒再探测一次
timeoutSeconds: 5 # http检测请求的超时时间
successThreshold: 1 # 检测到有1次成功则认为服务是`就绪`
failureThreshold: 3 # 检测到有3次失败则认为服务是`未就绪`
livenessProbe: # 定义只有http检测容器6222端口请求返回是 200-400,否则就重启pod
httpGet:
scheme: HTTP
path: /check
port: 6222
initialDelaySeconds: 10
periodSeconds: 5
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
#-----------------------------------------
readinessProbe:
exec:
command:
- sh
- -c
- "redis-cli ping"
initialDelaySeconds: 5
periodSeconds: 10
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
livenessProbe:
exec:
command:
- sh
- -c
- "redis-cli ping"
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
#-----------------------------------------
readinessProbe:
tcpSocket:
port: 9092
initialDelaySeconds: 15
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 9092
initialDelaySeconds: 15
periodSeconds: 10Health Check 在生产中应用场景
Health Check 在 业务生产中滚动更新(rolling update)的应用场景 对于运维人员来说,将服务的新项目代码更新上线,确保其稳定运行是一项很关键,且重复性很高的任务,
在传统模式下,我们一般是用saltsatck或者ansible等批量管理工具来推送代码到各台服务器上进行更新,
那么在K8s上,这个更新流程就被简化了,在后面高阶章节我会讲到CI/CD自动化流程,大致就是开发人员开发好代码上传代码仓库即会触发CI/CD流程,这之间基本无需运维人员的参与。
那么在这么高度自动化的流程中,我们运维人员怎么确保服务能稳定上线呢?Health Check里面的Readiness 能发挥很关键的作用,这个其实在上面也有讲过,这里我们再以实例来说一遍,加深印象:
我们准备一个deployment资源的yaml文件
# myapp-v1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mytest
spec:
replicas: 10 # 这里准备10个数量的pod
selector:
matchLabels:
app: mytest
template:
metadata:
labels:
app: mytest
spec:
containers:
- name: mytest
image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
args:
- /bin/sh
- -c
- sleep 10; touch /tmp/healthy; sleep 30000
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10
periodSeconds: 5# 运行
# kubectl apply -f myapp-v1.yaml --record
deployment.apps/mytest created
# 等待一会,可以看到所有pod已正常运行
# kubectl get pod
NAME READY STATUS RESTARTS AGE
mytest-6984d777c5-4gh86 1/1 Running 0 25s
mytest-6984d777c5-4mdrv 1/1 Running 0 25s
mytest-6984d777c5-dfwzl 1/1 Running 0 25s
mytest-6984d777c5-dr2vb 1/1 Running 0 24s
mytest-6984d777c5-dvxrf 1/1 Running 0 25s
mytest-6984d777c5-kd8wq 1/1 Running 0 25s
mytest-6984d777c5-lkfmc 1/1 Running 0 25s
mytest-6984d777c5-nnvn4 1/1 Running 0 24s
mytest-6984d777c5-qv5pr 1/1 Running 0 25s
mytest-6984d777c5-zrnhh 1/1 Running 0 2接着我们来准备更新这个服务,并且人为模拟版本故障来进行观察
# myapp-v2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mytest
spec:
strategy:
rollingUpdate:
maxSurge: 35% # 滚动更新的副本总数最大值(以10的基数为例):10 + 10 * 35% = 13.5 --> 14
maxUnavailable: 35% # 可用副本数最大值(默认值两个都是25%): 10 - 10 * 35% = 6.5 --> 7
replicas: 10
selector:
matchLabels:
app: mytest
template:
metadata:
labels:
app: mytest
spec:
containers:
- name: mytest
image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
args:
- /bin/sh
- -c
- sleep 30000 # 可见这里并没有生成/tmp/healthy这个文件,所以下面的检测必然失败
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10
periodSeconds: 5更新的这个v2版本里面不会生成/tmp/healthy文件,那么自动是无法通过Readiness 检测的,详情如下:
# 更新
# kubectl apply -f myapp-v2.yaml --record
deployment.apps/mytest configured
# 查看deployment状态
# kubectl get deployment mytest
NAME READY UP-TO-DATE AVAILABLE AGE
mytest 7/10 7 7 14m
# READY 现在正在运行的只有7个pod
# UP-TO-DATE 表示当前已经完成更新的副本数:即 7 个新副本
# AVAILABLE 表示当前处于 READY 状态的副本数
# 查看pod状态
# kubectl get pod
NAME READY STATUS RESTARTS AGE
mytest-589f5b7cd-7chm5 0/1 Running 0 100s
mytest-589f5b7cd-8nx5l 0/1 Running 0 99s
mytest-589f5b7cd-9lrcj 0/1 Running 0 100s
mytest-589f5b7cd-dkfxf 0/1 Running 0 99s
mytest-589f5b7cd-dn6rg 0/1 Running 0 100s
mytest-589f5b7cd-z7rmj 0/1 Running 0 100s
mytest-589f5b7cd-z8tdp 0/1 Running 0 99s
mytest-6984d777c5-4gh86 1/1 Running 0 14m
mytest-6984d777c5-4mdrv 1/1 Running 0 14m
mytest-6984d777c5-dfwzl 1/1 Running 0 14m
mytest-6984d777c5-dr2vb 1/1 Running 0 14m
mytest-6984d777c5-kd8wq 1/1 Running 0 14m
mytest-6984d777c5-lkfmc 1/1 Running 0 14m
mytest-6984d777c5-qv5pr 1/1 Running 0 14m
# 上面可以看到,由于 Readiness 检测一直没通过,所以新版本的pod都是Not ready状态的,这样就保证了错误的业务代码不会被外界请求到# kubectl describe deployment mytest
# 下面截取一些这里需要的关键信息
......
Replicas: 10 desired | 7 updated | 14 total | 7 available | 7 unavailable
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 5m55s deployment-controller Scaled up replica set mytest-d9f48585b to 10
Normal ScalingReplicaSet 3m53s deployment-controller Scaled up replica set mytest-7657789bc7 to 4 # 启动4个新版本的pod
Normal ScalingReplicaSet 3m53s deployment-controller Scaled down replica set mytest-d9f48585b to 7 # 将旧版本pod数量降至7
Normal ScalingReplicaSet 3m53s deployment-controller Scaled up replica set mytest-7657789bc7 to 7 # 新增3个启动至7个新版本综合上面的分析,我们很真实的模拟一次K8s上次错误的代码上线流程,所幸的是这里有Health Check的Readiness检测帮我们屏蔽了有错误的副本,不至于被外面的流量请求到,同时保留了大部分旧版本的pod,因此整个服务的业务并没有因这此更新失败而受到影响。
接下来我们详细分析下滚动更新的原理,为什么上面服务新版本创建的pod数量是7个,同时只销毁了3个旧版本的pod呢?
原因就在于这段配置:
strategy:
rollingUpdate:
maxSurge: 35%
maxUnavailable: 35%我们不显式配置这段的话,默认值均是25%
滚动更新通过参数maxSurge和maxUnavailable来控制pod副本数量的更新替换。
maxSurge 这个参数控制滚动更新过程中pod副本总数超过设定总副本数量的上限。maxSurge 可以是具体的整数(比如 3),也可以是百分比,向上取整。maxSurge 默认值为 25%
在上面测试的例子里面,pod的总副本数量是10,那么在更新过程中,总副本数量的上限大最值计划公式为:
10 + 10 * 35% = 13.5 --> 14
我们查看下更新deployment的描述信息:
Replicas: 10 desired | 7 updated | 14 total | 7 available | 7 unavailable
旧版本available 的数量7个 + 新版本unavailable`的数量7个 = 总数量 14 total
maxUnavailable-00:38:51 这个参数控制滚动更新过程中不可用的pod副本总数量的值,同样,maxUnavailable 可以是具体的整数(比如 3),也可以是百分百,向下取整。maxUnavailable 默认值为 25%。
在上面测试的例子里面,pod的总副本数量是10,那么要保证正常可用的pod副本数量为:
10 - 10 * 35% = 6.5 --> 7
所以我们在上面查看的描述信息里,7 available 正常可用的pod数量值就为7
maxSurge 值越大,初始创建的新副本数量就越多;maxUnavailable 值越大,初始销毁的旧副本数量就越多。
正常更新理想情况下,我们这次版本发布案例滚动更新的过程是:
首先创建4个新版本的pod,使副本总数量达到14个 然后再销毁3个旧版本的pod,使可用的副本数量降为7个 当这3个旧版本的pod被 成功销毁后,可再创建3个新版本的pod,使总的副本数量保持为14个 当新版本的pod通过Readiness 检测后,会使可用的pod副本数量增加超过7个 然后可以继续销毁更多的旧版本的pod,使整体可用的pod数量回到7个 随着旧版本的pod销毁,使pod副本总数量低于14个,这样就可以继续创建更多的新版本的pod 这个新增销毁流程会持续地进行,最终所有旧版本的pod会被新版本的pod逐渐替换,整个滚动更新完成 而我们这里的实际情况是在第4步就卡住了,新版本的pod数量无法能过Readiness 检测。上面的描述信息最后面的事件部分的日志也详细说明了这一切:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 5m55s deployment-controller Scaled up replica set mytest-d9f48585b to 10
Normal ScalingReplicaSet 3m53s deployment-controller Scaled up replica set mytest-7657789bc7 to 4 # 启动4个新版本的pod
Normal ScalingReplicaSet 3m53s deployment-controller Scaled down replica set mytest-d9f48585b to 7 # 将旧版本pod数量降至7
Normal ScalingReplicaSet 3m53s deployment-controller Scaled up replica set mytest-7657789bc7 to 7 # 新增3个启动至7个新版本这里按正常的生产处理流程,在获取足够的新版本错误信息提交给开发分析后,我们可以通过kubectl rollout undo 来回滚到上一个正常的服务版本:
# 先查看下要回滚版本号前面的数字,这里为1
# # kubectl rollout history deployment mytest
deployment.apps/mytest
REVISION CHANGE-CAUSE
1 kubectl apply --filename=myapp-v1.yaml --record=true
2 kubectl apply --filename=myapp-v2.yaml --record=true
# 回滚
# kubectl rollout undo deployment mytest --to-revision=1
deployment.apps/mytest rolled back
# kubectl get deployment mytest
NAME READY UP-TO-DATE AVAILABLE AGE
mytest 10/10 10 10 96m
# kubectl get pod
NAME READY STATUS RESTARTS AGE
mytest-589f5b7cd-7chm5 0/1 Terminating 0 115m
mytest-589f5b7cd-8nx5l 0/1 Terminating 0 115m
mytest-589f5b7cd-9lrcj 0/1 Terminating 0 115m
mytest-589f5b7cd-dkfxf 0/1 Terminating 0 115m
mytest-589f5b7cd-dn6rg 0/1 Terminating 0 115m
mytest-589f5b7cd-z7rmj 0/1 Terminating 0 115m
mytest-589f5b7cd-z8tdp 0/1 Terminating 0 115m
mytest-6984d777c5-4gh86 1/1 Running 0 127m
mytest-6984d777c5-4mdrv 1/1 Running 0 127m
mytest-6984d777c5-7lg7z 1/1 Running 0 29s
mytest-6984d777c5-8v2k9 1/1 Running 0 29s
mytest-6984d777c5-9d9rl 1/1 Running 0 29s
mytest-6984d777c5-dfwzl 1/1 Running 0 127m
mytest-6984d777c5-dr2vb 1/1 Running 0 127m
mytest-6984d777c5-kd8wq 1/1 Running 0 127m
mytest-6984d777c5-lkfmc 1/1 Running 0 127m
mytest-6984d777c5-qv5pr 1/1 Running 0 127mOK,到这里为止,我们真实的模拟了一次有问题的版本发布及回滚,并且可以看到,在这整个过程中,虽然出现了问题,但我们的业务依然是没有受到任何影响的,这就是K8s的魅力所在。
(四)Service、Endpoint、Endpoint Slices
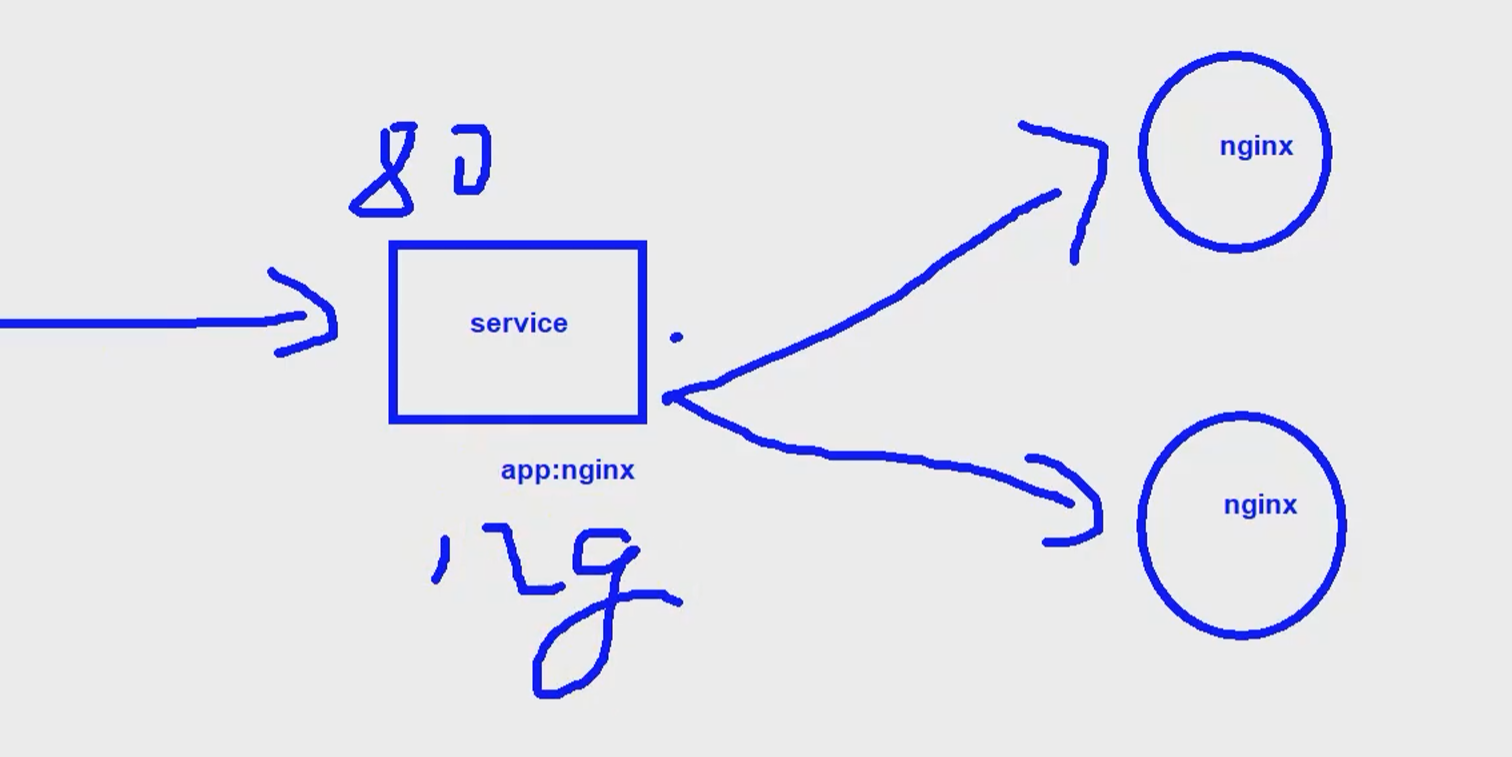
Service
K8s是运维人员的救星,为什么这么说呢,因为它里面的运行机制能确保你需要运行的服务,一直保持所期望的状态。
还是以上面nginx服务举例,我们不能确保其pod运行的node节点什么时候会宕掉,同时在pod环节也说过,pod的IP每次重启都会发生改变,所以我们不应该期望K8s的pod是健壮的,而是要按最坏的打算来假设服务pod中的容器会因为代码有bug、所以node节点不稳定等等因素发生故障而挂掉。
这时候如果我们用的Deployment,那么它的controller会通过动态创建新pod到可用的node上,同时删除旧的pod来保证应用整体的健壮性;并且流量入口这块用一个能固定IP的service来充当抽象的内部负载均衡器,提供pod的访问,所以这里等于就是K8s成为了一个7 x 24小时在线处理服务pod故障的运维机器人。
nginx.yaml
启动Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: new-nginx
labels:
app: new-nginx
spec:
replicas: 2
selector:
matchLabels:
app: new-nginx
template:
metadata:
labels:
app: new-nginx
spec:
containers:
#--------------------------------------------------
- name: new-nginx
image: nginx:1.21.6
# image: nginx:1.25.1
env:
- name: TZ
value: Asia/Shanghai
ports:
- containerPort: 80
volumeMounts:
- name: html-files
mountPath: "/usr/share/nginx/html"
#--------------------------------------------------
- name: busybox
image: registry.cn-shanghai.aliyuncs.com/acs/busybox:v1.29.2
# image: nicolaka/netshoot
args:
- /bin/sh
- -c
- >
while :; do
if [ -f /html/index.html ];then
echo "[$(date +%F\ %T)] ${MY_POD_NAMESPACE}-${MY_POD_NAME}-${MY_POD_IP}" > /html/index.html
sleep 1
else
touch /html/index.html
fi
done
env:
- name: TZ
value: Asia/Shanghai
- name: MY_POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: MY_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
volumeMounts:
- name: html-files
mountPath: "/html"
- mountPath: /etc/localtime
name: tz-config
#--------------------------------------------------
volumes:
- name: html-files
emptyDir:
medium: Memory
sizeLimit: 10Mi
- name: tz-config
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai# 先清除
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 25d
# kubectl get pod
No resources found in default namespace.# 启动
# kubectl apply -f new-nginx.yaml
deployment.apps/new-nginx created
# 查看
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
new-nginx-854cf59647-4s4hx 2/2 Running 0 34s 172.20.139.87 10.0.1.203 <none> <none>
new-nginx-854cf59647-fvj8m 2/2 Running 0 34s 172.20.139.86 10.0.1.203 <none> <none>创建一个service服务来提供固定IP轮巡访问上面创建的nginx服务的2个pod(nodeport)
# 给这个nginx的deployment生成一个service(简称svc)
# 命令生成yaml配置
kubectl expose deployment new-nginx --port=80 --target-port=80 --dry-run=client -o yaml
# 我们可以先把上面的yaml配置导出为svc.yaml提供后面,这里就直接用命令行创建了# 命令直接创建service服务
# kubectl expose deployment new-nginx --port=80 --target-port=80
service/new-nginx exposed
# 查看service
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 25d
new-nginx ClusterIP 10.68.3.120 <none> 80/TCP 8s
# 看下自动关联生成的endpoint
# kubectl get endpoints new-nginx
NAME ENDPOINTS AGE
new-nginx 172.20.139.86:80,172.20.139.87:80 2m36s
# 接下来测试下svc的负载均衡效果吧
# curl 10.68.3.120
[2024-05-17 13:09:49] default-new-nginx-854cf59647-4s4hx-172.20.139.87
# curl 10.68.3.120
[2024-05-17 13:09:51] default-new-nginx-854cf59647-fvj8m-172.20.139.86
# kubectl get endpointslices.discovery.k8s.io
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
kubernetes IPv4 6443 10.0.1.201,10.0.1.202 25d
new-nginx-mk6lc IPv4 80 172.20.139.86,172.20.139.87 6m29s# 修改svc的类型来提供外部访问
# 方式一:
# kubectl patch svc nginx -p '{"spec":{"type":"NodePort"}}'
service/nginx patched
# 方式二:
# kubectl edit svc new-nginx
service/new-nginx edited
spec.type由ClusterIP修改为NodePort
# 重新查看service服务
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 25d
new-nginx NodePort 10.68.3.120 <none> 80:31995/TCP 9m13s
# 使用宿主机IP轮询
# curl 10.0.1.201:31995
[2024-05-17 13:17:01] default-new-nginx-854cf59647-4s4hx-172.20.139.87
# curl 10.0.1.201:31995
[2024-05-17 13:17:02] default-new-nginx-854cf59647-fvj8m-172.20.139.86
# 其他节点IP
# curl 10.0.1.202:31995
[2024-05-17 13:50:47] default-new-nginx-854cf59647-4s4hx-172.20.139.87
# curl 10.0.1.202:31995
[2024-05-17 13:50:49] default-new-nginx-854cf59647-fvj8m-172.20.139.86生产一般使用ingress给外部访问,NodePort可以在内部机房使用
Endpoints
分析下这个svc的yaml配置
apiVersion: v1 # <<<<<< v1 是 Service 的 apiVersion
kind: Service # <<<<<< 指明当前资源的类型为 Service
metadata:
creationTimestamp: null
labels:
app: new-nginx
name: new-nginx # <<<<<< Service 的名字为 new-nginx
spec:
ports:
- port: 80 # <<<<<< 将 Service 的 80 端口映射到 Pod 的 80 端口,使用 TCP 协议
protocol: TCP
targetPort: 80
selector:
app: new-nginx # <<<<<< selector 指明挑选那些 label 为 run: new-nginx 的 Pod 作为 Service 的后端
status:
loadBalancer: {}# kubectl describe svc new-nginx
Name: new-nginx
Namespace: default
Labels: app=new-nginx
Annotations: <none>
Selector: app=new-nginx
Type: NodePort
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.68.3.120
IPs: 10.68.3.120
Port: <unset> 80/TCP
TargetPort: 80/TCP
NodePort: <unset> 31995/TCP
Endpoints: 172.20.139.86:80,172.20.139.87:80
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>Cluster 集群
Endpoints列出了2个pod的IP和端口,pod的ip是在容器中配置的,那么这里Service cluster IP又是在哪里配置的呢?cluster ip又是自律映射到pod ip上的呢?
# 首先看下kube-proxy的配置
# cat /etc/systemd/system/kube-proxy.service
[Unit]
Description=Kubernetes Kube-Proxy Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
[Service]
WorkingDirectory=/var/lib/kube-proxy
ExecStart=/opt/kube/bin/kube-proxy \
--config=/var/lib/kube-proxy/kube-proxy-config.yaml
Restart=always
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
# 再看提到的kube-proxy-config.yaml
# cat /var/lib/kube-proxy/kube-proxy-config.yaml
kind: KubeProxyConfiguration
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
clientConnection:
kubeconfig: "/etc/kubernetes/kube-proxy.kubeconfig"
# 根据clusterCIDR 判断集群内部和外部流量,配置clusterCIDR选项后,kube-proxy 会对访问 Service IP 的请求做 SNAT
clusterCIDR: "172.20.0.0/16"
conntrack:
maxPerCore: 32768
min: 131072
tcpCloseWaitTimeout: 1h0m0s
tcpEstablishedTimeout: 24h0m0s
healthzBindAddress: 0.0.0.0:10256
# hostnameOverride 值必须与 kubelet 的对应一致,否则 kube-proxy 启动后会找不到该 Node,从而不会创建任何 iptables 规则
hostnameOverride: "10.0.1.201"
metricsBindAddress: 0.0.0.0:10249
mode: "ipvs" #<------- 我们在最开始部署kube-proxy的时候就设定它的转发模式为ipvs,因为默认的iptables在存在大量svc的情况下性能很低
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: False
syncPeriod: 30s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
# 看下本地网卡,会有一个ipvs的虚拟网卡
# ip addr | grep ipvs
5: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether 86:c5:70:bd:8b:4b brd ff:ff:ff:ff:ff:ff
inet 10.68.0.1/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.68.0.2/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.68.118.185/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.68.108.228/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.68.3.120/32 scope global kube-ipvs0 # <-------- SVC的IP配置在这里
valid_lft forever preferred_lft forever
# 来看下lvs的虚拟服务器列表
# ipvsadm -ln | grep 10.68.3.120
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.68.3.120:80 rr #<----------- SVC转发Pod的明细在这里
-> 172.20.139.86:80 Masq 1 0 0
-> 172.20.139.87:80 Masq 1 0 0除了直接用cluster ip,以及上面说到的NodePort模式来访问Service,我们还可以用K8s的DNS来访问
直接使用new-nginx访问
# 我们前面装好的CoreDNS,来提供K8s集群的内部DNS访问
# kubectl -n kube-system get deployment,pod|grep dns
deployment.apps/coredns 1/1 1 1 25d
pod/coredns-65bc7b648d-92n9q 1/1 Running 10 (119m ago) 25d
pod/node-local-dns-9p4pd 1/1 Running 12 (119m ago) 25d
pod/node-local-dns-kcdtq 1/1 Running 9 (121m ago) 25d
pod/node-local-dns-rfwkm 1/1 Running 12 (120m ago) 25dcoredns是一个DNS服务器,每当有新的Service被创建的时候,coredns就会添加该Service的DNS记录,然后我们通过serviceName.namespaceName就可以来访问到对应的pod了,下面来演示下:
# 创建测试命名空间
# kubectl create ns test
namespace/test created
# 创建pod
# kubectl -n test run -it --rm busybox --image=registry.cn-shanghai.aliyuncs.com/acs/busybox:v1.29.2 -- sh
# --rm代表等我退出这个pod后,它会被自动删除,当作一个临时pod在用
If you don't see a command prompt, try pressing enter.
/ # ping new-nginx.default -w 1
PING new-nginx.default (10.68.3.120): 56 data bytes
--- new-nginx.default ping statistics ---
2 packets transmitted, 0 packets received, 100% packet loss
# 跨命名空间可能ping不通
# 轮询请求
/ # wget new-nginx.default
Connecting to new-nginx.default (10.68.3.120:80)
index.html 100% |*******************************************************************************| 71 0:00:00 ETA
'index.html' saved
/ # cat index.html
[2024-05-17 14:55:36] default-new-nginx-854cf59647-4s4hx-172.20.139.87
/ # rm index.html
/ # wget new-nginx.default
Connecting to new-nginx.default (10.68.3.120:80)
index.html 100% |*******************************************************************************| 71 0:00:00 ETA
/ # cat index.html
[2024-05-17 14:56:38] default-new-nginx-854cf59647-fvj8m-172.20.139.86Endpoint Slices
在 Kubernetes 网络系统中,Endpoint 和 Endpoint Slices 都是非常重要的资源。Endpoint 和 Endpoint Slices 都负责追踪网络端点,但 Endpoint Slices 是 Kubernetes 1.16 之后引入的,用于替代 Endpoint 的新资源。
Endpoint Slices 是 Kubernetes 中的 API 对象,用于表示集群中的网络端点。与其前身 Endpoint 相比,Endpoint Slices 提供了一个更加可扩展和可扩展的方式来追踪网络端点。
Endpoint Slices 的主要优势包括:
- 可扩展性:Endpoint Slices 比 Endpoints 更具可扩展性。在大型集群中,使用 Endpoint 可能会导致网络性能问题,因为每次服务的后端更改时,都会更新所有的 Endpoints。但是,Endpoint Slices 分散了这些信息,使得网络流量可以在多个 Endpoint Slices 中分布,从而提高了可扩展性。
- 内置拓扑信息:Endpoint Slices 支持内置的拓扑信息,如 nodeName、zone、region 等,这些信息可以用于实现更复杂的网络路由,以优化网络流量。
- 多地址类型:Endpoint Slices 支持多种地址类型,包括 IPv4、IPv6 和 FQDN(完全限定域名)。
Endpoint Slices 的主要构成部分包括:
- 地址:这是 Endpoint Slices 中的主要字段,用于存储网络端点的地址。
- 端口:Endpoint Slices 可以包含多个端口,每个端点可以关联一个或多个端口。
- 条件:Endpoint Slices 包含关于端点的一些条件信息,例如端点是否就绪。
- 拓扑:这些字段用于表示端点的拓扑信息,例如 nodeName、zone、region 等。
在 Kubernetes 中,Endpoint Slices 控制器默认会为每个服务创建和管理 Endpoint Slices。当创建新的 Kubernetes 服务时,相应的 Endpoint Slices 也会被创建,当服务的后端发生更改时,Endpoint Slices 也会相应地更新。
apiVersion: discovery.k8s.io/v1beta1
kind: EndpointSlice
metadata:
name: example-abc
labels:
kubernetes.io/service-name: example
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
nodeName: node-1
zone: us-central1-a
以上是一个 EndpointSlices 的简单例子。在此 YAML 文件中,我们定义了一个名为 “example-abc” 的 EndpointSlice,它追踪名为 “example” 的服务的网络端点。这个 EndpointSlice 包含一个端点,地址为 “10.1.2.3”,端口为 80,位于节点 “node-1” 和区域 “us-central1-a”。
总的来说,Endpoint Slices 是 Kubernetes 网络系统的重要组成部分,它提供了一种高效且可扩展的方式来追踪网络端点,使得 Kubernetes 网络可以更好地扩展和优化。
通过svc访问非K8s的服务
service生产小技巧 通过svc来访问非K8s上的服务
上面我们提到了创建service后,会自动创建对应的endpoint,这里面的关键在于 selector: app: nginx 基于lables标签选择了一组存在这个标签的pod,然而在我们创建svc时,如果没有定义这个selector,那么系统是不会自动创建endpoint的,我们可不可以手动来创建这个endpoint呢?
答案是可以的,在生产中,我们可以通过创建不带selector的Service,然后创建同样名称的endpoint,来关联K8s集群以外的服务,这个具体能带给我们运维人员什么好处呢,就是我们可以直接复用K8s上的ingress(这个后面会讲到,现在我们就当它是一个nginx代理),来访问K8s集群以外的服务,省去了自己搭建前面Nginx代理服务器的麻烦
开始实践测试
这里我们挑选node-2节点,用python运行一个简易web服务器
# python2 -m SimpleHTTPServer 9999
Serving HTTP on 0.0.0.0 port 9999 ...然后我们用之前学会的方法,来生成svc和endpoint的yaml配置,并修改成如下内容,并保存为mysvc.yaml
注意Service和Endpoints的名称必须一致
注意这里把两个资源的yaml写在一个文件内,在实际生产中,我们经常会这么做,方便对一个服务的所有资源进行统一管理,不同资源之间用"---"来分隔
apiVersion: v1
kind: Service
metadata:
name: mysvc
namespace: default
spec:
type: ClusterIP
ports:
- port: 80
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: mysvc
namespace: default
subsets:
- addresses:
- ip: 10.0.1.202
nodeName: 10.0.1.202
ports:
- port: 9999
protocol: TCP开始创建并测试
# kubectl apply -f mysvc.yaml
service/mysvc created
endpoints/mysvc created
# kubectl get svc,endpoints |grep mysvc
service/mysvc ClusterIP 10.68.205.178 <none> 80/TCP 25s
endpoints/mysvc 10.0.1.202:9999 25s
# curl 10.68.205.178
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"><html>
<title>Directory listing for /</title>
<body>
<h2>Directory listing for /</h2>
<hr>
<ul>
<li><a href=".ansible/">.ansible/</a>
<li><a href=".bash_history">.bash_history</a>
<li><a href=".bashrc">.bashrc</a>
<li><a href=".cache/">.cache/</a>
<li><a href=".kube/">.kube/</a>
<li><a href=".profile">.profile</a>
<li><a href=".ssh/">.ssh/</a>
<li><a href=".viminfo">.viminfo</a>
<li><a href=".Xauthority">.Xauthority</a>
<li><a href="init.sh">init.sh</a>
</ul>
<hr>
</body>
</html>
# 我们回到node-2节点上,可以看到有一条刚才的访问日志打印出来了
10.0.1.201 - - [18/May/2024 00:10:20] "GET / HTTP/1.1" 200 -外部网络如何访问到Service呢?
在上面其实已经给大家演示过了将Service的类型改为NodePort,然后就可以用node节点的IP加端口就能访问到Service了,我们这里来详细分析下原理,以便加深印象
# 我们看下先创建的nginx service的yaml配置
# kubectl get svc nginx -o yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2020-11-25T03:55:05Z"
labels:
app: nginx
managedFields: # 在新版的K8s运行的资源配置里面,会输出这么多的配置信息,这里我们可以不用管它,实际我们在创建时,这些都是忽略的
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
e:metadata:
e:labels:
.: {}
e:app: {}
e:spec:
e:externalTrafficPolicy: {}
e:ports:
.: {}
k:{"port":80,"protocol":"TCP"}:
.: {}
e:port: {}
e:protocol: {}
e:targetPort: {}
e:selector:
.: {}
e:app: {}
e:sessionAffinity: {}
e:type: {}
manager: kubectl
operation: Update
time: "2020-11-25T04:00:28Z"
name: nginx
namespace: default
resourceVersion: "591029"
selfLink: /api/v1/namespaces/default/services/nginx
uid: 84fea557-e19d-486d-b879-13743c603091
spec:
clusterIP: 10.68.18.121
externalTrafficPolicy: Cluster
ports:
- nodePort: 20651 # 我们看下这里,它定义的一个nodePort配置,并分配了20651端口,因为我们先前创建时并没有指定这个配置,所以它是随机生成的
port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}# 我们看下apiserver的配置
# cat /etc/systemd/system/kube-apiserver.service
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
[Service]
ExecStart=/opt/kube/bin/kube-apiserver \
--allow-privileged=true \
--anonymous-auth=false \
--api-audiences=api,istio-ca \
--authorization-mode=Node,RBAC \
--bind-address=10.0.1.201 \
--client-ca-file=/etc/kubernetes/ssl/ca.pem \
--endpoint-reconciler-type=lease \
--etcd-cafile=/etc/kubernetes/ssl/ca.pem \
--etcd-certfile=/etc/kubernetes/ssl/kubernetes.pem \
--etcd-keyfile=/etc/kubernetes/ssl/kubernetes-key.pem \
--etcd-servers=https://10.0.1.201:2379,https://10.0.1.202:2379,https://10.0.1.203:2379 \
--kubelet-certificate-authority=/etc/kubernetes/ssl/ca.pem \
--kubelet-client-certificate=/etc/kubernetes/ssl/kubernetes.pem \
--kubelet-client-key=/etc/kubernetes/ssl/kubernetes-key.pem \
--secure-port=6443 \
--service-account-issuer=https://kubernetes.default.svc \
--service-account-signing-key-file=/etc/kubernetes/ssl/ca-key.pem \
--service-account-key-file=/etc/kubernetes/ssl/ca.pem \
--service-cluster-ip-range=10.68.0.0/16 \
--service-node-port-range=30000-32767 \ # 这就是NodePor随机生成端口的范围,这个在我们部署时就指定了
--tls-cert-file=/etc/kubernetes/ssl/kubernetes.pem \
--tls-private-key-file=/etc/kubernetes/ssl/kubernetes-key.pem \
--requestheader-client-ca-file=/etc/kubernetes/ssl/ca.pem \
--requestheader-allowed-names= \
--requestheader-extra-headers-prefix=X-Remote-Extra- \
--requestheader-group-headers=X-Remote-Group \
--requestheader-username-headers=X-Remote-User \
--proxy-client-cert-file=/etc/kubernetes/ssl/aggregator-proxy.pem \
--proxy-client-key-file=/etc/kubernetes/ssl/aggregator-proxy-key.pem \
--enable-aggregator-routing=true \
--v=2
Restart=always
RestartSec=5
Type=notify
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target# NodePort端口会在所在K8s的node节点上都生成一个同样的端口,这就使我们无论所以哪个node的ip接端口都能方便的访问到Service了,但在实际生产中,这个NodePort不建议经常使用,因为它会造成node上端口管理混乱,等用到了ingress后,你就不会想使用NodePort模式了,这个接下来会讲到
[root@node-1 ~]# ipvsadm -ln|grep -C6 20651
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
......
TCP 10.0.1.201:20651 rr # 这里
-> 172.20.139.72:80 Masq 1 0 0
-> 172.20.217.72:80 Masq 1 0 0
[root@node-2 mnt]# ipvsadm -ln|grep -C6 20651
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
......
TCP 10.0.1.202:20651 rr # 这里
-> 172.20.139.72:80 Masq 1 0 0
-> 172.20.217.72:80 Masq 1 0 0生产中Service的调优
原版:
# 先把nginx的pod数量调整为1,方便呆会观察
# kubectl scale deployment nginx --replicas=1
deployment.apps/nginx scaled
# 看下这个nginx的pod运行情况,-o wide显示更详细的信息,这里可以看到这个pod运行在node 203上面
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-f89759699-qlc8q 1/1 Running 0 3h27m 172.20.139.72 10.0.1.203 <none> <none>
# 我们先直接通过pod运行的node的IP来访问测试
[root@node-1 ~]# curl 10.0.1.203:20651
nginx-f89759699-qlc8q
# 可以看到日志显示这条请求的来源IP是203,而不是node-1的IP 10.0.1.201
# 注: kubectl logs --tail=1 代表查看这个pod的日志,并只显示倒数第一条
[root@node-1 ~]# kubectl logs --tail=1 nginx-f89759699-qlc8q
10.0.1.203 - - [25/Nov/2020:07:22:54 +0000] "GET / HTTP/1.1" 200 22 "-" "curl/7.29.0" "-"
# 再来通过201来访问
[root@node-1 ~]# curl 10.0.1.201:20651
nginx-f89759699-qlc8q
# 可以看到显示的来源IP非node节点的
[root@node-1 ~]# kubectl logs --tail=1 nginx-f89759699-qlc8q
172.20.84.128 - - [25/Nov/2020:07:23:18 +0000] "GET / HTTP/1.1" 200 22 "-" "curl/7.29.0" "-"
# 这就是一个虚拟网卡转发的
[root@node-1 ~]# ip a|grep -wC2 172.20.84.128
9: tunl0@NONe: <NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 172.20.84.128/32 brd 172.20.84.128 scope global tunl0
valid_lft forever preferred_lft forever
# 可以看下lvs的虚拟服务器列表,正好是转到我们要访问的pod上的
[root@node-1 ~]# ipvsadm -ln|grep -A1 172.20.84.128
TCP 172.20.84.128:20651 rr
-> 172.20.139.72:80 Masq 1 0 0
详细处理流程如下:
* 客户端发送数据包 10.0.1.201:20651
* 10.0.1.201 用自己的IP地址替换数据包中的源IP地址(SNAT)
* 10.0.1.201 使用 pod IP 替换数据包上的目标 IP
* 数据包路由到 10.0.1.203 ,然后路由到 endpoint
* pod的回复被路由回 10.0.1.201
* pod的回复被发送回客户端
client
\ ^
\ \
v \
10.0.1.203 <--- 10.0.1.201
| ^ SNAT
| | --->
v |
endpoint为避免这种情况, Kubernetes 具有保留客户端IP 的功能。设置 service.spec.externalTrafficPolicy 为 Local 会将请求代理到本地端点,不将流量转发到其他节点,从而保留原始IP地址。如果没有本地端点,则丢弃发送到节点的数据包,因此您可以在任何数据包处理规则中依赖正确的客户端IP。
# 设置 service.spec.externalTrafficPolicy 字段如下:
# kubectl patch svc nginx -p '{"spec":{"externalTrafficPolicy":"Local"}}'
service/nginx patched
# 现在通过非pod所在node节点的IP来访问是不通了
[root@node-1 ~]# curl 10.0.1.201:20651
curl: (7) Failed connect to 10.0.1.201:20651; Connection refused
# 通过所在node的IP发起请求正常
[root@node-1 ~]# curl 10.0.1.203:20651
nginx-f89759699-qlc8q
# 可以看到日志显示的来源IP就是201,这才是我们想要的结果
[root@node-1 ~]# kubectl logs --tail=1 nginx-f89759699-qlc8q
10.0.1.201 - - [25/Nov/2020:07:33:42 +0000] "GET / HTTP/1.1" 200 22 "-" "curl/7.29.0" "-"
# 去掉这个优化配置也很简单
# kubectl patch svc nginx -p '{"spec":{"externalTrafficPolicy":""}}'自己实机运行结果:
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
new-nginx-854cf59647-4s4hx 2/2 Running 0 3h22m 172.20.139.87 10.0.1.203 <none> <none>
new-nginx-854cf59647-fvj8m 2/2 Running 0 3h22m 172.20.139.86 10.0.1.203 <none> <none>
# 查看端口
# kubectl get svc new-nginx -o yaml
spec:
ports:
- nodePort: 31995
# 我们先直接通过pod运行的node的IP来访问测试
# curl 10.0.1.203:31995
[2024-05-17 16:25:10] default-new-nginx-854cf59647-4s4hx-172.20.139.87
# curl 10.0.1.203:31995
[2024-05-17 16:25:15] default-new-nginx-854cf59647-fvj8m-172.20.139.86
# 可以看到日志显示这条请求的来源IP是203,而不是node-1的IP 10.0.1.201
# 注: kubectl logs --tail=1 代表查看这个pod的日志,并只显示倒数第一条
# kubectl logs --tail=1 new-nginx-854cf59647-fvj8m
Defaulted container "new-nginx" out of: new-nginx, busybox
10.0.1.203 - - [18/May/2024:00:25:16 +0800] "GET / HTTP/1.1" 200 71 "-" "curl/7.81.0" "-"
# 再来通过201来访问
# curl 10.0.1.201:31995
[2024-05-17 16:28:08] default-new-nginx-854cf59647-4s4hx-172.20.139.87
# 可以看到显示的来源IP非node节点的
# kubectl logs --tail=1 new-nginx-854cf59647-4s4hx
Defaulted container "new-nginx" out of: new-nginx, busybox
172.20.84.128 - - [18/May/2024:00:28:09 +0800] "GET / HTTP/1.1" 200 71 "-" "curl/7.81.0" "-"
# 这就是一个虚拟网卡转发的
# ip a|grep -wC2 172.20.84.128
8: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 172.20.84.128/32 scope global tunl0
valid_lft forever preferred_lft forever
# 可以看下lvs的虚拟服务器列表,正好是转到我们要访问的pod上的
# ipvsadm -ln|grep -A1 172.20.84.128
TCP 172.20.84.128:31260 rr
-> 10.0.1.202:9999 Masq 1 0 0
TCP 172.20.84.128:31995 rr
-> 172.20.139.86:80 Masq 1 0 0
详细处理流程如下:
* 客户端发送数据包 10.0.1.201:31995
* 10.0.1.201 用自己的IP地址替换数据包中的源IP地址(SNAT)
* 10.0.1.201 使用 pod IP 替换数据包上的目标 IP
* 数据包路由到 10.0.1.203 ,然后路由到 endpoint
* pod的回复被路由回 10.0.1.201
* pod的回复被发送回客户端
client
\ ^
\ \
v \
10.0.1.203 <--- 10.0.1.201
| ^ SNAT
| | --->
v |
endpoint
增加网络开销
为避免这种情况, Kubernetes 具有保留客户端IP 的功能。设置 service.spec.externalTrafficPolicy 为 Local 会将请求代理到本地端点,不将流量转发到其他节点,从而保留原始IP地址。如果没有本地端点,则丢弃发送到节点的数据包,因此您可以在任何数据包处理规则中依赖正确的客户端IP。
# 设置 service.spec.externalTrafficPolicy 字段如下:
# kubectl patch svc new-nginx -p '{"spec":{"externalTrafficPolicy":"Local"}}'
service/nginx patched
# 现在通过非pod所在node节点的IP来访问是不通了
# (能访问通,视频也通)
[root@node-1 ~]# curl 10.0.1.201:31995
curl: (7) Failed connect to 10.0.1.201:20651; Connection refused
# 通过所在node的IP发起请求正常
# (只有一个work节点,不好观测,还是会负载均衡)
[root@node-1 ~]# curl 10.0.1.203:31995
nginx-f89759699-qlc8q
# 可以看到日志显示的来源IP就是201,这才是我们想要的结果
[root@node-1 ~]# kubectl logs --tail=1 nginx-f89759699-qlc8q
10.0.1.201 - - [25/Nov/2020:07:33:42 +0000] "GET / HTTP/1.1" 200 22 "-" "curl/7.29.0" "-"
# 去掉这个优化配置也很简单
# kubectl patch svc nginx -p '{"spec":{"externalTrafficPolicy":""}}'注意:这样会带来个什么问题呢,如是一旦pod发生重启飘移到了另一台node节点上,而你用的IP还是203的话就会访问不到服务了,这个利弊需要自己权衡,解决方法可以用nodeSelector将服务的pod固定在哪几台node节点上运行,这样ip还是在我们控制的范围了,我们现在就来试试nodeSelector的效果吧
# 修改好yaml配置
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: nginx
name: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources: {}
nodeSelector: # <--- 这里
apps/nginx: "true" # <--- 基于这个label来选择
status: {}然后我们这里在需要指定运行的node上打上label
注意:这里提醒下,对于在K8s中运行的资源,大部分都是基于label标签来作服务关系的选择,这里仅仅是以node这个资源来作的演示,其它如Service、Deployment等等,都是可以用类似命令来label操作的
# kubectl label node 10.0.1.201 apps/nginx=true
node/10.0.1.201 labeled
# kubectl get node 10.0.1.201 --show-labels |grep nginx
10.0.1.201 Ready master 5d3h v1.18.12 apps/nginx=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,cb/ingress-controller-ready=true,kubernetes.io/arch=amd64,kubernetes.io/hostname=10.0.1.201,kubernetes.io/os=linux,kubernetes.io/role=master,kubevirt.io/schedulable=true开始基于yaml配置创建服务
# kubectl apply -f nginx.yaml
deployment.apps/nginx created
# 因为之前是把pod数量改成了2,所以这里看到2个pod都跑在201上面了,因为我只在201上面做了label标记
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-867c95f465-kkxnm 0/1 ContainerCreating 0 5s <none> 10.0.1.201 <none> <none>
nginx-867c95f465-njv78 0/1 ContainerCreating 0 5s <none> 10.0.1.201 <none> <none>
# 我们这里还是先将数量改成1个
# kubectl scale deployment nginx --replicas=1
deployment.apps/nginx scaled
# 后面无论这个pod怎么重启,它都只会在打了label apps/nginx=true的节点上运行了
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-867c95f465-njv78 1/1 Running 0 32s 172.20.84.132 10.0.1.201 <none> <none>pod小怪战斗(作业)
创建一个nginx的deployment,pod副本数量设为2,并为它创建一个Service服务,尝试用Service的IP来请求pod,并且通过创建一个临时busybox的pod,通过DNS来请求pod
创建命名空间
1.创建一个nginx的deployment,pod副本数量设为2
apiVersion: apps/v1
kind: Deployment
metadata:
name: new-nginx
labels:
app: new-nginx
spec:
replicas: 2
selector:
matchLabels:
app: new-nginx
template:
metadata:
labels:
app: new-nginx
spec:
containers:
#--------------------------------------------------
- name: new-nginx
image: nginx:1.21.6
# image: nginx:1.25.1
env:
- name: TZ
value: Asia/Shanghai
ports:
- containerPort: 80
volumeMounts:
- name: html-files
mountPath: "/usr/share/nginx/html"
#--------------------------------------------------
- name: busybox
image: registry.cn-shanghai.aliyuncs.com/acs/busybox:v1.29.2
# image: nicolaka/netshoot
args:
- /bin/sh
- -c
- >
while :; do
if [ -f /html/index.html ];then
echo "[$(date +%F\ %T)] ${MY_POD_NAMESPACE}-${MY_POD_NAME}-${MY_POD_IP}" > /html/index.html
sleep 1
else
touch /html/index.html
fi
done
env:
- name: TZ
value: Asia/Shanghai
- name: MY_POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: MY_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
volumeMounts:
- name: html-files
mountPath: "/html"
- mountPath: /etc/localtime
name: tz-config
#--------------------------------------------------
volumes:
- name: html-files
emptyDir:
medium: Memory
sizeLimit: 10Mi
- name: tz-config
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai# 启动
# kubectl -n test apply -f new-nginx.yaml并为它创建一个Service服务
# 命令直接创建service服务
# kubectl -n test expose deployment new-nginx --port=80 --target-port=80
service/new-nginx exposed尝试用Service的IP来请求pod
# 查看service
# kubectl -n test get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
new-nginx ClusterIP 10.68.7.170 <none> 80/TCP 18s并且通过创建一个临时busybox的pod
# 创建pod
# kubectl -n test run -it --rm busybox --image=registry.cn-shanghai.aliyuncs.com/acs/busybox:v1.29.2 -- sh
If you don't see a command prompt, try pressing enter.
/ #通过DNS来请求pod
/ # wget new-nginx.test
Connecting to new-nginx.test (10.68.7.170:80)
index.html 100% |********************************| 68 0:00:00 ETA
/ # cat index.html
[2024-05-17 17:12:32] test-new-nginx-854cf59647-l2lt2-172.20.139.91(五)Labels资源身份标签
labels标签,在kubernetes我们会经常见到,它的功能非常关键,就相关于服务pod的身份证信息。如果我们创建一个deployment资源,它之所有能守护下面启动的N个pod以达到期望的数据,service之所以能把流量准确无误的转发到指定的pod上去,归根结底都是labels在这里起作用。
# 先删除上节课的pod
# kubectl delete deployment.apps new-nginx
deployment.apps "new-nginx" deleted
# 我们先来创建一个nginx的deployment资源
# kubectl create deployment nginx --image=nginx:1.21.6 --replicas=3
# 等服务pod都运行好,这时候按我们期待的状态就是3个pod,没问题
# kubectl get pod -w
# 我们再来基于这个nginx的deployment来创建一个service服务
# kubectl expose deployment nginx --port=80 --target-port=80 --name=nginx
# 直接利用svc的ip来请求下,发现都是正常的对吧
# kubectl get svc nginx# 查看svc的Selector和Endpoints
# kubectl describe svc nginx
Name: nginx
Namespace: default
Labels: app=nginx
Annotations: <none>
Selector: app=nginx
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.68.242.169
IPs: 10.68.242.169
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 172.20.139.103:80,172.20.139.104:80,172.20.139.99:80
Session Affinity: None
Events: <none>我们现在来修改其中一个pod的label,你会发现这个pod会被deployment抛弃,因为失去了labels这个标签,deployment已经不认识这个pod了,它就成了无主的pod,这时我们直接删除这个pod,它就会直接消失,就和我们用kubectl run 一个独立的pod资源一样
# 这个时候我来来修改下svc资源的选择labels,看看会出现什么情况
# kubectl patch services nginx -p '{"spec":{"selector":{"app": "nginxaaa"}}}'
# 这时再请求这个svc的ip,你会发现已经请求不通了,这也证明了它已经关联不到后面对应label的pod了
# curl 10.68.242.169
curl: (7) Failed to connect to 10.68.242.169 port 80 after 0 ms: Connection refused
# 我们修改回来后,会发现一切恢复正常了
kubectl patch services nginx -p '{"spec":{"selector":{"app": "nginx"}}}'labels受namespace管控,在同一个namespace下面的服务labels,如果只有一个,就需要注意其唯一性,不要有重复的存在,不然服务就会跑串,出现一些奇怪的现象,我们在资源中可以配置多个lables来一起组合使用,这样就会大大降低重复的情况了。
生产案例
扩容时用新建deployment的方式,但是还是同一个service管
# 多deployment混合运行模式
# 首先导出多服务配置 kubectl get deployments.apps nginx -o yaml > nginx-other.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx-other # 把名称换一下
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1.21.6
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
# kubectl describe svc nginx
# kubectl apply -f nginx-other.yaml
# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 5m57s
nginx-other 1/1 1 1 14s
# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 26d <none>
mysvc NodePort 10.68.205.178 <none> 80:31260/TCP 15h <none>
nginx ClusterIP 10.68.242.169 <none> 80/TCP 12m app=nginx
# kubectl get deployment -l app=nginx -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx 3/3 3 3 21m nginx nginx:1.21.6 app=nginx
nginx-other 1/1 1 1 7m15s nginx nginx:1.21.6 app=nginx
# kubectl get pod -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-6f648b8457-bff9d 1/1 Running 0 16m
nginx-6f648b8457-jvf9h 1/1 Running 0 16m
nginx-6f648b8457-zjnmc 1/1 Running 0 16m
nginx-other-6f648b8457-2tlqk 1/1 Running 0 112s