第28关 Prometheus监控
(一) Prometheus介绍
对于运维开发人员来说,不管是哪个平台服务,监控都是非常关键重要的。
在传统服务(固定网络或服务器)里面,我们通常会到zabbix、open-falcon、netdata来做服务的监控,但对于目前主流的K8s平台(pod名称随机、ip随机)来说,由于服务pod会被调度到任何机器上运行,且pod挂掉后会被自动重启,并且我们也需要有更好的自动服务发现功能来实现服务报警的自动接入,实现更高效的运维报警,这里我们需要用到K8s的监控实现Prometheus(云原生首选)(Go语言、二进制文件),它是基于Google内部监控系统的开源实现。
参加面试的话监控必不可少,会针对公司现有现有的监控体系来问你。有没有用过、怎么监控的、监控什么维度。了解监控软件的架构,怎么使用更好的监控规则配置。针对监控软件做二次开发更好的符合公司特性。
zabbix(大部分、主流)架构原因,机器多的时候有性能问题
open-falcon(小米开源,但不怎么更新了,替代品是夜莺,原班人马开发)
netdata(秒级)
Prometheus架构图
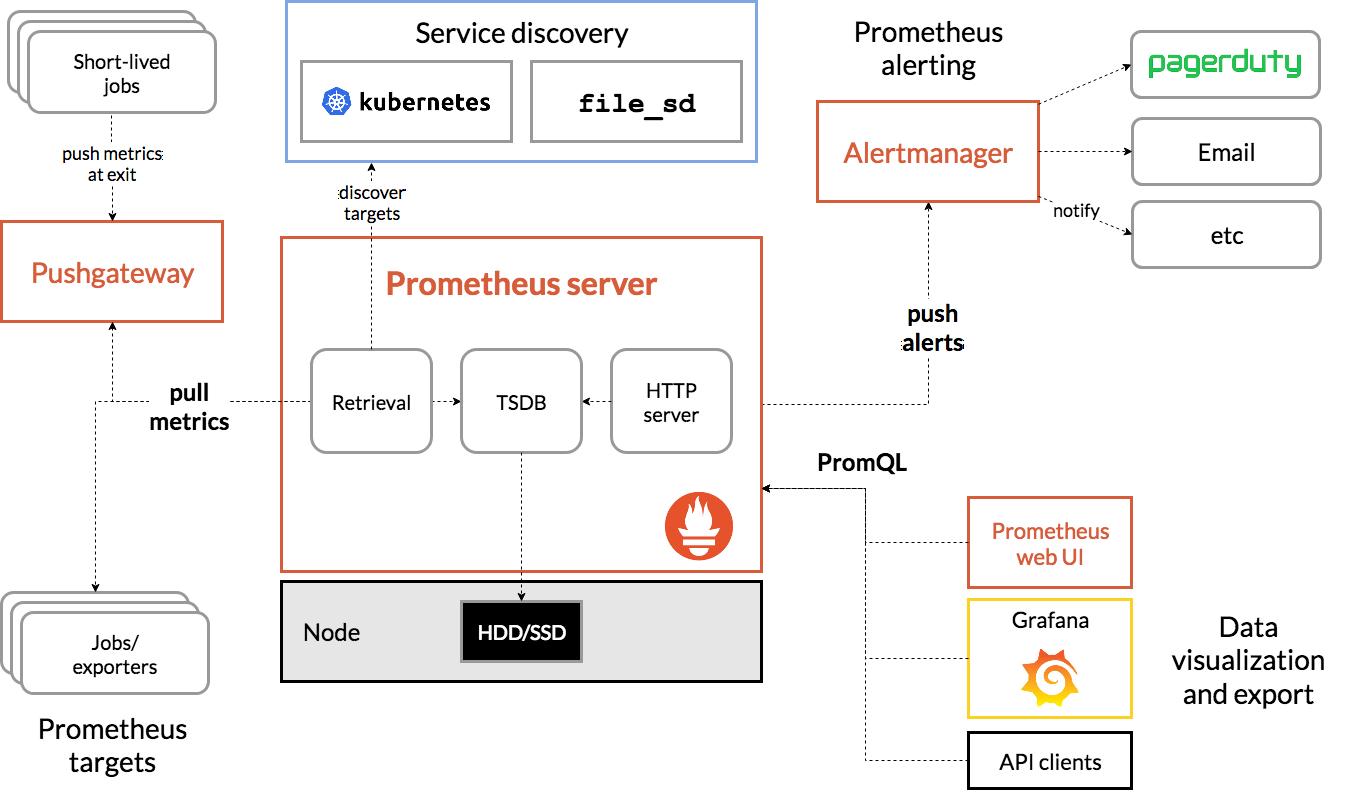
TSDB 数据存储 可以看文档
Pushgateway:边缘节点网络不好可以设置一个gateway网关,比如一个北京一个北美,可以在香港设置一个网关
Alertmannager:告警模块 钉钉、企业微信 Webhook形式报警推送信息
Prometheus是由golang语言编写,这样它的部署实际上是比较简单的,就一个服务的二进制包加上对应的配置文件即可运行,然而这种方式的部署过程繁琐并且效率低下,我们这里就不以这种传统的形式来部署Prometheus来实现K8s集群的监控了,而是会用到Prometheus-Operator来进行Prometheus监控服务的安装,这也是我们生产中常用的安装方式。
从本质上来讲Prometheus属于是典型的有状态应用,而其有包含了一些自身特有的运维管理和配置管理方式。而这些都无法通过Kubernetes原生提供的应用管理概念实现自动化。为了简化这类应用程序的管理复杂度,CoreOS率先引入了Operator的概念,并且首先推出了针对在Kubernetes下运行和管理Etcd的Etcd Operator。并随后推出了Prometheus Operator。
Prometheus Operator的工作原理
从概念上来讲Operator就是针对管理特定应用程序的,在Kubernetes基本的Resource和Controller的概念上,以扩展Kubernetes api的形式。帮助用户创建,配置和管理复杂的有状态应用程序。从而实现特定应用程序的常见操作以及运维自动化。
在Kubernetes中我们使用Deployment、DamenSet,StatefulSet来管理应用Workload,使用Service,Ingress来管理应用的访问方式,使用ConfigMap和Secret来管理应用配置。我们在集群中对这些资源的创建,更新,删除的动作都会被转换为事件(Event),Kubernetes的Controller Manager负责监听这些事件并触发相应的任务来满足用户的期望。这种方式我们成为声明式,用户只需要关心应用程序的最终状态,其它的都通过Kubernetes来帮助我们完成,通过这种方式可以大大简化应用的配置管理复杂度。
而除了这些原生的Resource资源以外,Kubernetes还允许用户添加自己的自定义资源(Custom Resource)。并且通过实现自定义Controller来实现对Kubernetes的扩展。
如下所示,是Prometheus Operator的架构示意图:
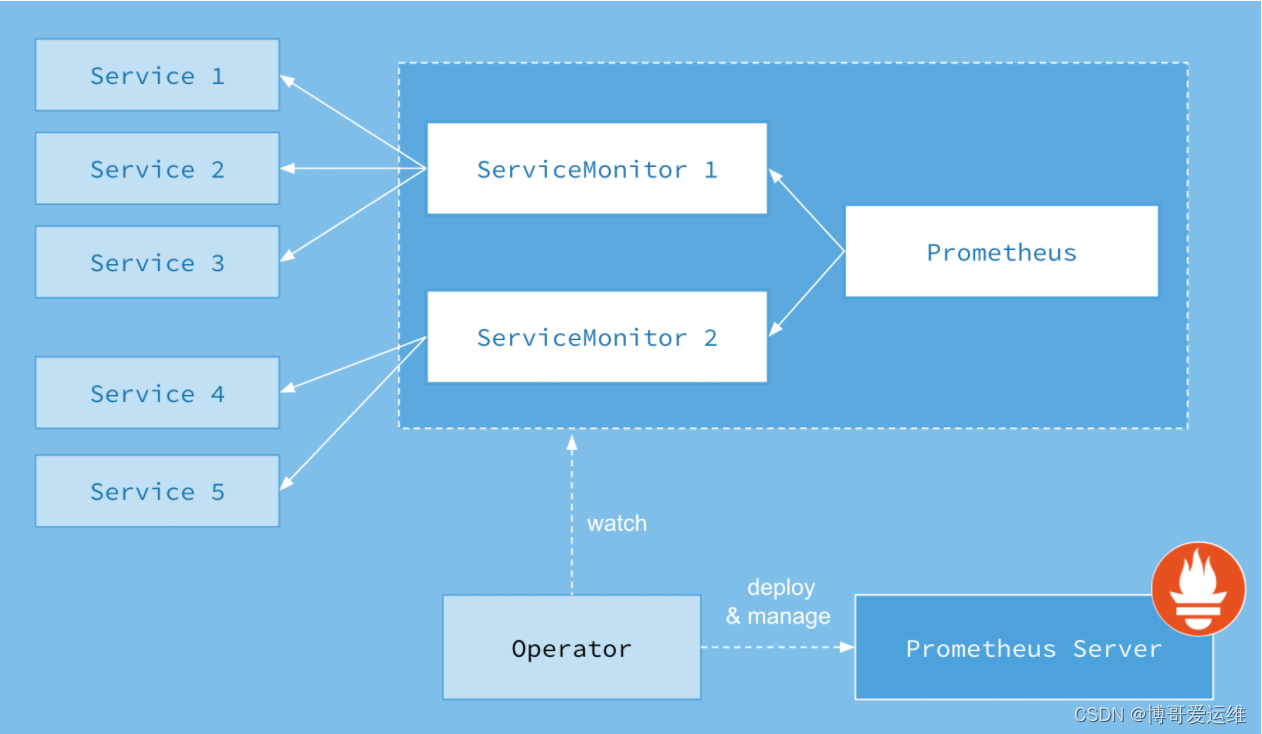
Prometheus的本职就是一组用户自定义的CRD资源以及Controller的实现,Prometheus Operator负责监听这些自定义资源的变化,并且根据这些资源的定义自动化的完成如Prometheus Server自身以及配置的自动化管理工作。
Prometheus Operator能做什么
要了解Prometheus Operator能做什么,其实就是要了解Prometheus Operator为我们提供了哪些自定义的Kubernetes资源,列出了Prometheus Operator目前提供的️4类资源:
- Prometheus:声明式创建和管理Prometheus Server实例;
- ServiceMonitor:负责声明式的管理监控配置;
- PrometheusRule:负责声明式的管理告警配置;
- Alertmanager:声明式的创建和管理Alertmanager实例。
简言之,Prometheus Operator能够帮助用户自动化的创建以及管理Prometheus Server以及其相应的配置。
(二) operator安装
用prometheus-operator来安装整套prometheus服务
https://github.com/prometheus-operator/kube-prometheus/releases
下载
1. 解压下载的代码包
wget https://github.com/prometheus-operator/kube-prometheus/archive/refs/tags/v0.13.0.zip
unzip v0.13.0.zip
rm -f v0.13.0.zip && cd kube-prometheus-0.13.0
2. 这里先看下有哪些镜像
# find ./ -type f |xargs egrep 'image: quay.io|image: registry.k8s.io|image: grafana|image: docker.io'|awk '{print $3}'|sort|uniq
quay.io/prometheus-operator/prometheus-config-reloader:v0.67.1 # 注意:这个镜像配置比较特殊,上面命令过滤不出来
grafana/grafana:9.5.3
docker.io/cloudnativelabs/kube-router
quay.io/brancz/kube-rbac-proxy:v0.14.2
quay.io/fabxc/prometheus_demo_service
quay.io/prometheus/alertmanager:v0.26.0
quay.io/prometheus/blackbox-exporter:v0.24.0
quay.io/prometheus/node-exporter:v1.6.1
quay.io/prometheus-operator/prometheus-operator:v0.67.1
quay.io/prometheus/prometheus:v2.46.0
registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2
registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.11.1 # 这两个直接卡住
# 由于上面的镜像中,有部分国内网络无法正常摘取,所以博哥将上述所有镜像已转存至docker hub上,用下面命令批量替换下镜像地址即可
find ./ -type f |xargs sed -ri 's+quay.io/.*/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+docker.io/cloudnativelabs/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+grafana/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+registry.k8s.io/.*/+docker.io/bogeit/+g'修改镜像
理论上quay.io等已经配置镜像源,应该不会拉取不到,尝试推送到自建harbor
博哥方法
搜索镜像
2. 这里先看下有哪些镜像
# cd kube-prometheus-0.13.0
# find ./ -type f |xargs egrep 'image: quay.io|image: registry.k8s.io|image: grafana|image: docker.io'|awk '{print $3}'|sort|uniq
grafana/grafana:9.5.3
docker.io/cloudnativelabs/kube-router
quay.io/brancz/kube-rbac-proxy:v0.14.2
quay.io/fabxc/prometheus_demo_service
quay.io/prometheus/alertmanager:v0.26.0
quay.io/prometheus/blackbox-exporter:v0.24.0
quay.io/prometheus/node-exporter:v1.6.1
quay.io/prometheus-operator/prometheus-operator:v0.67.1
quay.io/prometheus/prometheus:v2.46.0
registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2
registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.11.1 # 这两个直接卡住
quay.io/prometheus-operator/prometheus-config-reloader:v0.67.1 # 注意:这个镜像配置比较特殊,上面命令过滤不出来修改
# 由于上面的镜像中,有部分国内网络无法正常摘取,所以博哥将上述所有镜像已转存至docker hub上,用下面命令批量替换下镜像地址即可
find ./ -type f |xargs sed -ri 's+quay.io/.*/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+docker.io/cloudnativelabs/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+grafana/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+registry.k8s.io/.*/+docker.io/bogeit/+g'
暴力修改后
# find ./ -type f |xargs egrep -n 'docker.io/bogeit'|sort
./docs/blackbox-exporter.md:31:* `_config.imageRepos.blackboxExporter`: the name of the blackbox exporter image to deploy. Defaults to `docker.io/bogeit/blackbox-exporter`.
./docs/community-support.md:63:For documentation, check the [Grafana docs](https://grafana.com/docs/docker.io/bogeit/latest/).
./docs/community-support.md:67:For bugs, use the GitHub [issue tracker](https://github.com/docker.io/bogeit/docker.io/bogeit/issues/new/choose).
./docs/customizations/developing-prometheus-rules-and-grafana-dashboards.md:356:We recommend using the [grafonnet](https://github.com/docker.io/bogeit/grafonnet-lib/) library for jsonnet,
./docs/customizations/using-custom-container-registry.md:12:$ docker pull docker.io/bogeit/alertmanager:v0.16.2
./docs/customizations/using-custom-container-registry.md:13:$ docker tag docker.io/bogeit/alertmanager:v0.16.2
./docs/kube-prometheus-on-kubeadm.md:119:kubectl --namespace="$NAMESPACE" apply -f manifests/docker.io/bogeit/grafana-credentials.yaml
./docs/weave-net-support.md:14:4. [Grafana Dashboard for Weave Net](https://grafana.com/docker.io/bogeit/dashboards/11789) This will setup the per Weave Net pod level monitoring for Weave Net.
./docs/weave-net-support.md:15:5. [Grafana Dashboard for Weave Net(Cluster)](https://grafana.com/docker.io/bogeit/dashboards/11804) This will setup the cluster level monitoring for Weave Net.
./examples/example-app/example-app.yaml:36: image: docker.io/bogeit/prometheus_demo_service
./examples/grafana-ldap.jsonnet:13: config_file: '/etc/docker.io/bogeit/ldap.toml',
./examples/prometheus-thanos.jsonnet:18: baseImage: 'docker.io/bogeit/thanos',
./examples/thanos-sidecar.jsonnet:11: image: 'docker.io/bogeit/thanos:v0.19.0',
./.github/workflows/kind/kube-router.yaml:50: image: docker.io/bogeit/kube-router
./.github/workflows/kind/kube-router.yaml:89: image: docker.io/bogeit/kube-router
./jsonnetfile.lock.json:27: "remote": "https://github.com/docker.io/bogeit/grafana.git",
./jsonnetfile.lock.json:37: "remote": "https://github.com/docker.io/bogeit/grafonnet-lib.git",
./jsonnetfile.lock.json:47: "remote": "https://github.com/docker.io/bogeit/grafonnet-lib.git",
./jsonnetfile.lock.json:57: "remote": "https://github.com/docker.io/bogeit/jsonnet-libs.git",
./jsonnet/kube-prometheus/addons/config-mixins.libsonnet:18:// docker.io/bogeit/addon-resizer
./jsonnet/kube-prometheus/addons/config-mixins.libsonnet:19:// docker.io/bogeit/grafana -> grafana $repository/grafana
./jsonnet/kube-prometheus/components/grafana.libsonnet:1:local kubernetesGrafana = import 'github.com/brancz/kubernetes-docker.io/bogeit/docker.io/bogeit/grafana.libsonnet';
./jsonnet/kube-prometheus/components/grafana.libsonnet:30: runbookURLPattern: 'https://runbooks.prometheus-operator.dev/runbooks/docker.io/bogeit/%s',
./jsonnet/kube-prometheus/components/grafana.libsonnet:50: (import 'github.com/docker.io/bogeit/docker.io/bogeit/grafana-mixin/mixin.libsonnet') +
./jsonnet/kube-prometheus/jsonnetfile.json:16: "remote": "https://github.com/docker.io/bogeit/grafana",
./jsonnet/kube-prometheus/main.libsonnet:40: alertmanager: 'docker.io/bogeit/alertmanager:v' + $.values.common.versions.alertmanager,
./jsonnet/kube-prometheus/main.libsonnet:41: blackboxExporter: 'docker.io/bogeit/blackbox-exporter:v' + $.values.common.versions.blackboxExporter,
./jsonnet/kube-prometheus/main.libsonnet:42: grafana: 'docker.io/bogeit/grafana:' + $.values.common.versions.grafana,
./jsonnet/kube-prometheus/main.libsonnet:43: kubeStateMetrics: 'docker.io/bogeit/kube-state-metrics:v' + $.values.common.versions.kubeStateMetrics,
./jsonnet/kube-prometheus/main.libsonnet:44: nodeExporter: 'docker.io/bogeit/node-exporter:v' + $.values.common.versions.nodeExporter,
./jsonnet/kube-prometheus/main.libsonnet:45: prometheus: 'docker.io/bogeit/prometheus:v' + $.values.common.versions.prometheus,
./jsonnet/kube-prometheus/main.libsonnet:46: prometheusAdapter: 'docker.io/bogeit/prometheus-adapter:v' + $.values.common.versions.prometheusAdapter,
./jsonnet/kube-prometheus/main.libsonnet:47: prometheusOperator: 'docker.io/bogeit/prometheus-operator:v' + $.values.common.versions.prometheusOperator,
./jsonnet/kube-prometheus/main.libsonnet:48: prometheusOperatorReloader: 'docker.io/bogeit/prometheus-config-reloader:v' + $.values.common.versions.prometheusOperator,
./jsonnet/kube-prometheus/main.libsonnet:49: kubeRbacProxy: 'docker.io/bogeit/kube-rbac-proxy:v' + $.values.common.versions.kubeRbacProxy,
./manifests/alertmanager-alertmanager.yaml:13: image: docker.io/bogeit/alertmanager:v0.26.0
./manifests/blackboxExporter-deployment.yaml:33: image: docker.io/bogeit/blackbox-exporter:v0.24.0
./manifests/blackboxExporter-deployment.yaml:87: image: docker.io/bogeit/kube-rbac-proxy:v0.14.2
./manifests/grafana-deployment.yaml:33: image: docker.io/bogeit/grafana:9.5.3
./manifests/grafana-deployment.yaml:61: - mountPath: /etc/docker.io/bogeit/provisioning/datasources
./manifests/grafana-deployment.yaml:64: - mountPath: /etc/docker.io/bogeit/provisioning/dashboards
./manifests/grafana-prometheusRule.yaml:20: runbook_url: https://runbooks.prometheus-operator.dev/runbooks/docker.io/bogeit/grafanarequestsfailing
./manifests/kubeStateMetrics-deployment.yaml:35: image: docker.io/bogeit/kube-state-metrics:v2.9.2
./manifests/kubeStateMetrics-deployment.yaml:58: image: docker.io/bogeit/kube-rbac-proxy:v0.14.2
./manifests/kubeStateMetrics-deployment.yaml:83: image: docker.io/bogeit/kube-rbac-proxy:v0.14.2
./manifests/nodeExporter-daemonset.yaml:40: image: docker.io/bogeit/node-exporter:v1.6.1
./manifests/nodeExporter-daemonset.yaml:75: image: docker.io/bogeit/kube-rbac-proxy:v0.14.2
./manifests/prometheusAdapter-deployment.yaml:41: image: docker.io/bogeit/prometheus-adapter:v0.11.1
./manifests/prometheusOperator-deployment.yaml:32: - --prometheus-config-reloader=docker.io/bogeit/prometheus-config-reloader:v0.67.1
./manifests/prometheusOperator-deployment.yaml:33: image: docker.io/bogeit/prometheus-operator:v0.67.1
./manifests/prometheusOperator-deployment.yaml:55: image: docker.io/bogeit/kube-rbac-proxy:v0.14.2
./manifests/prometheus-prometheus.yaml:21: image: docker.io/bogeit/prometheus:v2.46.0
./scripts/generate-versions.sh:61: "grafana": "$(get_version "docker.io/bogeit/grafana")",
./scripts/get-new-changelogs.sh:30: get_changelog_url "docker.io/bogeit/grafana" "${version}"自己修改
先来看看是怎么安装的:
kubectl create -f manifests/setup
kubectl create -f manifests/再看看这个项目的说明:
这个项目旨在作为一个库使用(即意图不是让你创建这个仓库的修改副本)。
尽管为了快速开始,这个仓库中已经检查了一个使用这个库(特别是使用example.jsonnet)生成的Kubernetes清单的编译版本,以便快速尝试内容。要尝试未经定制的堆栈,请运行:
- 使用
manifests目录中的配置创建监控堆栈:
# 创建命名空间和CRDs,然后在创建剩余资源之前等待它们可用
# 注意,由于某些CRD的大小,我们使用了kubectl服务器端应用功能,该功能自kubernetes 1.22起普遍可用。
# 如果您使用的是之前的kubernetes版本,这个功能可能不可用,您需要使用kubectl create。
kubectl apply --server-side -f manifests/setup
kubectl wait \
--for condition=Established \
--all CustomResourceDefinition \
--namespace=monitoring
kubectl apply -f manifests/我们首先创建命名空间和CustomResourceDefinitions,以避免在部署监控组件时出现竞争条件。或者,两个文件夹中的资源可以用一个命令kubectl apply --server-side -f manifests/setup -f manifests应用,但可能需要多次运行该命令,以确保所有组件都成功创建。
CustomResourceDefinition (CRD) 是 Kubernetes 中的一种机制,用于扩展 Kubernetes API,使用户能够定义和管理自定义资源。通过 CRD,用户可以在 Kubernetes 中创建新的 API 对象类型,这些类型不属于 Kubernetes 内置的资源(如 Pod、Service、Deployment 等),而是根据特定需求自定义的。
也就是说这个这个项目https://github.com/prometheus-operator/kube-prometheus,是一个用来生成Prometheus-Kubernetes资源清单的项目,里面有一个用这个库生成的示例资源清单,我们只是直接去使用了 。
那么怎么定制生成Kube-Prometheus呢
https://github.com/prometheus-operator/kube-prometheus/blob/main/docs/customizing.md
编译清单的示例:./build.sh example.jsonnet
example.jsonnet引入import 'kube-prometheus/main.libsonnet'
// to allow automatic upgrades of components, we store versions in autogenerated `versions.json` file and import it here
versions: {
alertmanager: error 'must provide version',
blackboxExporter: error 'must provide version',
grafana: error 'must provide version',
kubeStateMetrics: error 'must provide version',
nodeExporter: error 'must provide version',
prometheus: error 'must provide version',
prometheusAdapter: error 'must provide version',
prometheusOperator: error 'must provide version',
kubeRbacProxy: error 'must provide version',
configmapReload: error 'must provide version',
} + (import 'versions.json'),
images: {
alertmanager: 'quay.io/prometheus/alertmanager:v' + $.values.common.versions.alertmanager,
blackboxExporter: 'quay.io/prometheus/blackbox-exporter:v' + $.values.common.versions.blackboxExporter,
grafana: 'grafana/grafana:' + $.values.common.versions.grafana,
kubeStateMetrics: 'registry.k8s.io/kube-state-metrics/kube-state-metrics:v' + $.values.common.versions.kubeStateMetrics,
nodeExporter: 'quay.io/prometheus/node-exporter:v' + $.values.common.versions.nodeExporter,
prometheus: 'quay.io/prometheus/prometheus:v' + $.values.common.versions.prometheus,
prometheusAdapter: 'registry.k8s.io/prometheus-adapter/prometheus-adapter:v' + $.values.common.versions.prometheusAdapter,
prometheusOperator: 'quay.io/prometheus-operator/prometheus-operator:v' + $.values.common.versions.prometheusOperator,
prometheusOperatorReloader: 'quay.io/prometheus-operator/prometheus-config-reloader:v' + $.values.common.versions.prometheusOperator,
kubeRbacProxy: 'quay.io/brancz/kube-rbac-proxy:v' + $.values.common.versions.kubeRbacProxy,
configmapReload: 'ghcr.io/jimmidyson/configmap-reload:v' + $.values.common.versions.configmapReload,
},镜像仓库地址在main.libsonnet填写,镜像版本(tag)在versions.json
生成yaml文件的脚本:
#!/usr/bin/env bash
set -e
set -x
set -o pipefail
PATH="$(pwd)/tmp/bin:${PATH}"
# 确保从一个干净的 'manifests' 目录开始
rm -rf manifests
# 删除 manifests 目录及其所有内容(如果存在的话)
mkdir -p manifests/setup
# 创建 manifests 目录及其中的 setup 子目录
# 运行 jsonnet 工具,生成 YAML 文件
# -J vendor 指定 jsonnet 库路径为 vendor
# -m manifests 指定输出文件存放在 manifests 目录中
# "${1-example.jsonnet}" 使用第一个脚本参数(如果提供了),否则默认使用 example.jsonnet 文件
# xargs 命令将每个生成的文件转换为 YAML 格式
jsonnet -J vendor -m manifests "${1-example.jsonnet}" | xargs -I{} sh -c 'cat {} | gojsontoyaml > {}.yaml' -- {}
# 删除所有非 YAML 文件,确保 manifests 目录中只保留 .yaml 文件
find manifests -type f ! -name '*.yaml' -delete
# 删除 kustomization 文件(如果存在),以避免与其他 kustomize 配置文件冲突
rm -f kustomization所以用现成的资源文件的话就去修改文件夹manifests的镜像就行了
2. 这里先看下有哪些镜像
# cd kube-prometheus-0.13.0
# find ./manifests -type f |xargs egrep 'image: quay.io|image: registry.k8s.io|image: grafana|image: docker.io'|awk '{print $3}'|sort|uniq
grafana/grafana:9.5.3
quay.io/brancz/kube-rbac-proxy:v0.14.2
quay.io/prometheus/alertmanager:v0.26.0
quay.io/prometheus/blackbox-exporter:v0.24.0
quay.io/prometheus/node-exporter:v1.6.1
quay.io/prometheus-operator/prometheus-operator:v0.67.1
quay.io/prometheus/prometheus:v2.46.0
registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2
registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.11.1 # 这两个直接卡住
quay.io/prometheus-operator/prometheus-config-reloader:v0.67.1 # 注意:这个镜像配置比较特殊,上面命令过滤不出来
使用镜像quay.io/prometheus-operator/prometheus-config-reloader:v0.67.1作为Prometheus配置的重载器
# find ./manifests -type f | xargs egrep -n 'image: '
./manifests/grafana-deployment.yaml:33: image: grafana/grafana:9.5.3
./manifests/blackboxExporter-deployment.yaml:33: image: quay.io/prometheus/blackbox-exporter:v0.24.0
./manifests/blackboxExporter-deployment.yaml:60: image: jimmidyson/configmap-reload:v0.5.0
./manifests/blackboxExporter-deployment.yaml:87: image: quay.io/brancz/kube-rbac-proxy:v0.14.2
./manifests/nodeExporter-daemonset.yaml:40: image: quay.io/prometheus/node-exporter:v1.6.1
./manifests/nodeExporter-daemonset.yaml:75: image: quay.io/brancz/kube-rbac-proxy:v0.14.2
./manifests/alertmanager-alertmanager.yaml:13: image: quay.io/prometheus/alertmanager:v0.26.0
./manifests/prometheusAdapter-deployment.yaml:41: image: registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.11.1
./manifests/prometheusOperator-deployment.yaml:33: image: quay.io/prometheus-operator/prometheus-operator:v0.67.1
./manifests/prometheusOperator-deployment.yaml:55: image: quay.io/brancz/kube-rbac-proxy:v0.14.2
./manifests/prometheus-prometheus.yaml:21: image: quay.io/prometheus/prometheus:v2.46.0
./manifests/kubeStateMetrics-deployment.yaml:35: image: registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2
./manifests/kubeStateMetrics-deployment.yaml:58: image: quay.io/brancz/kube-rbac-proxy:v0.14.2
./manifests/kubeStateMetrics-deployment.yaml:83: image: quay.io/brancz/kube-rbac-proxy:v0.14.2
# find ./manifests -type f | xargs egrep -n 'prometheus-config-reloader'
./manifests/prometheusOperator-deployment.yaml:32: - --prometheus-config-reloader=quay.io/prometheus-operator/prometheus-config-reloader:v0.67.1
# 由于上面的镜像中,有部分国内网络无法正常摘取,所以博哥将上述所有镜像已转存至docker hub上,用下面命令批量替换下镜像地址即可
find ./ -type f |xargs sed -ri 's+quay.io/.*/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+docker.io/cloudnativelabs/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+grafana/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+registry.k8s.io/.*/+docker.io/bogeit/+g'manifests文件夹涉及的镜像
| 镜像名称 | 文件路径 | 行号 |
|---|---|---|
| grafana/grafana:9.5.3 | ./manifests/grafana-deployment.yaml | 33 |
| jimmidyson/configmap-reload:v0.5.0 | ./manifests/blackboxExporter-deployment.yaml | 60 |
| quay.io/brancz/kube-rbac-proxy:v0.14.2 | ./manifests/blackboxExporter-deployment.yaml | 87 |
| quay.io/brancz/kube-rbac-proxy:v0.14.2 | ./manifests/nodeExporter-daemonset.yaml | 75 |
| quay.io/brancz/kube-rbac-proxy:v0.14.2 | ./manifests/prometheusOperator-deployment.yaml | 55 |
| quay.io/brancz/kube-rbac-proxy:v0.14.2 | ./manifests/kubeStateMetrics-deployment.yaml | 58 |
| quay.io/brancz/kube-rbac-proxy:v0.14.2 | ./manifests/kubeStateMetrics-deployment.yaml | 83 |
| quay.io/prometheus/alertmanager:v0.26.0 | ./manifests/alertmanager-alertmanager.yaml | 13 |
| quay.io/prometheus/blackbox-exporter:v0.24.0 | ./manifests/blackboxExporter-deployment.yaml | 33 |
| quay.io/prometheus/node-exporter:v1.6.1 | ./manifests/nodeExporter-daemonset.yaml | 40 |
| quay.io/prometheus/prometheus:v2.46.0 | ./manifests/prometheus-prometheus.yaml | 21 |
| quay.io/prometheus-operator/prometheus-config-reloader:v0.67.1 | ./manifests/prometheusOperator-deployment.yaml | 32 |
| quay.io/prometheus-operator/prometheus-operator:v0.67.1 | ./manifests/prometheusOperator-deployment.yaml | 33 |
| registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2 | ./manifests/kubeStateMetrics-deployment.yaml | 35 |
| registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.11.1 | ./manifests/prometheusAdapter-deployment.yaml | 41 |
拉取上传到自己的Harbor镜像仓库
| 镜像名称 | Harbor仓库镜像名称 |
|---|---|
| grafana/grafana:9.5.3 | harbor.icurvestar.cn/docker.io/grafana/grafana:9.5.3 |
| jimmidyson/configmap-reload:v0.5.0 | harbor.icurvestar.cn/docker.io/jimmidyson/configmap-reload:v0.5.0 |
| quay.io/brancz/kube-rbac-proxy:v0.14.2 | harbor.icurvestar.cn/quay.io/brancz/kube-rbac-proxy:v0.14.2 |
| quay.io/prometheus/alertmanager:v0.26.0 | harbor.icurvestar.cn/quay.io/prometheus/alertmanager:v0.26.0 |
| quay.io/prometheus/blackbox-exporter:v0.24.0 | harbor.icurvestar.cn/quay.io/prometheus/blackbox-exporter:v0.24.0 |
| quay.io/prometheus/node-exporter:v1.6.1 | harbor.icurvestar.cn/quay.io/prometheus/node-exporter:v1.6.1 |
| quay.io/prometheus/prometheus:v2.46.0 | harbor.icurvestar.cn/quay.io/prometheus/prometheus:v2.46.0 |
| quay.io/prometheus-operator/prometheus-config-reloader:v0.67.1 | harbor.icurvestar.cn/quay.io/prometheus-operator/prometheus-config-reloader:v0.67.1 |
| quay.io/prometheus-operator/prometheus-operator:v0.67.1 | harbor.icurvestar.cn/quay.io/prometheus-operator/prometheus-operator:v0.67.1 |
| registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2 | harbor.icurvestar.cn/registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2 |
| registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.11.1 | harbor.icurvestar.cn/registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.11.1 |
博哥保存的镜像:
find ./ -type f |xargs sed -ri 's+quay.io/.*/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+docker.io/cloudnativelabs/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+grafana/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+registry.k8s.io/.*/+docker.io/bogeit/+g'
echo "quay.io/prometheus/alertmanager:v0.26.0" | sed -r 's+quay.io/.*/+docker.io/bogeit/+g'全部镜像按照:拉取-打标签-推送 流程来一遍
quay.io/prometheus/alertmanager:v0.26.0
# 拉取(官方)
docker pull quay.io/prometheus/alertmanager:v0.26.0
# 或者拉取博哥docker镜像仓库的(因为相对于quay.io,docker.io的镜像有加速)
docker pull docker.io/bogeit/alertmanager:v0.26.0
(可选)保存本地
docker save quay.io/prometheus/alertmanager:v0.26.0 > quay.io-prometheus-alertmanager_v0.26.0.tar
# 用博哥镜像仓库的:docker save docker.io/bogeit/alertmanager:v0.26.0 > quay.io-prometheus-alertmanager_v0.26.0.tar
打标签
docker tag quay.io/prometheus/alertmanager:v0.26.0 harbor.icurvestar.cn/quay.io/prometheus/alertmanager:v0.26.0
# 用博哥镜像仓库的:docker tag docker.io/bogeit/alertmanager:v0.26.0 harbor.icurvestar.cn/quay.io/prometheus/alertmanager:v0.26.0
推送
docker push harbor.icurvestar.cn/quay.io/prometheus/alertmanager:v0.26.0find ./ -type f |xargs sed -ri 's+quay.io/.*/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+docker.io/cloudnativelabs/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+grafana/+docker.io/bogeit/+g'
find ./ -type f |xargs sed -ri 's+registry.k8s.io/.*/+docker.io/bogeit/+g'针对处理
cd manifests/
# 1. 把image: quay.io、image: registry.k8s.io 带有image:统一添加
# harbor.icurvestar.cn/
find ./ -type f -exec sed -i 's+image: quay.io/+image: harbor.icurvestar.cn/quay.io/+g' {} +
find ./ -type f -exec sed -i 's+image: registry.k8s.io/+image: harbor.icurvestar.cn/registry.k8s.io/+g' {} +
# 2.修改grafana镜像地址
find ./ -type f -exec sed -i 's+image: grafana/grafana:+image: harbor.icurvestar.cn/docker.io/grafana/grafana:+g' {} +
# 3.jimmidyson/configmap-reload
find ./ -type f -exec sed -i 's+image: jimmidyson/configmap-reload:+image: harbor.icurvestar.cn/docker.io/jimmidyson/configmap-reload:+g' {} +
# 4.prometheus-config-reloader
find ./ -type f -exec sed -i 's+quay.io/prometheus-operator/prometheus-config-reloader:+harbor.icurvestar.cn/quay.io/prometheus-operator/prometheus-config-reloader:+g' {} +
# 检查
find ./ -type f | xargs egrep -n 'harbor.icurvestar.cn'修改后
# find ./ -type f | xargs egrep -n 'harbor.icurvestar.cn'
./grafana-deployment.yaml:33: image: harbor.icurvestar.cn/docker.io/grafana/grafana:9.5.3
./blackboxExporter-deployment.yaml:33: image: harbor.icurvestar.cn/quay.io/prometheus/blackbox-exporter:v0.24.0
./blackboxExporter-deployment.yaml:60: image: harbor.icurvestar.cn/docker.io/jimmidyson/configmap-reload:v0.5.0
./blackboxExporter-deployment.yaml:87: image: harbor.icurvestar.cn/quay.io/brancz/kube-rbac-proxy:v0.14.2
./nodeExporter-daemonset.yaml:40: image: harbor.icurvestar.cn/quay.io/prometheus/node-exporter:v1.6.1
./nodeExporter-daemonset.yaml:75: image: harbor.icurvestar.cn/quay.io/brancz/kube-rbac-proxy:v0.14.2
./alertmanager-alertmanager.yaml:13: image: harbor.icurvestar.cn/quay.io/prometheus/alertmanager:v0.26.0
./prometheusAdapter-deployment.yaml:41: image: harbor.icurvestar.cn/registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.11.1
./prometheusOperator-deployment.yaml:32: - --prometheus-config-reloader=harbor.icurvestar.cn/quay.io/prometheus-operator/prometheus-config-reloader:v0.67.1
./prometheusOperator-deployment.yaml:33: image: harbor.icurvestar.cn/quay.io/prometheus-operator/prometheus-operator:v0.67.1
./prometheusOperator-deployment.yaml:55: image: harbor.icurvestar.cn/quay.io/brancz/kube-rbac-proxy:v0.14.2
./prometheus-prometheus.yaml:21: image: harbor.icurvestar.cn/quay.io/prometheus/prometheus:v2.46.0
./kubeStateMetrics-deployment.yaml:35: image: harbor.icurvestar.cn/registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2
./kubeStateMetrics-deployment.yaml:58: image: harbor.icurvestar.cn/quay.io/brancz/kube-rbac-proxy:v0.14.2
./kubeStateMetrics-deployment.yaml:83: image: harbor.icurvestar.cn/quay.io/brancz/kube-rbac-proxy:v0.14.2推送到Harbor仓库
| 镜像名称 | Harbor仓库镜像名称 | |
|---|---|---|
| 1 | grafana/grafana:9.5.3 | harbor.icurvestar.cn/docker.io/grafana/grafana:9.5.3 |
| 2 | jimmidyson/configmap-reload:v0.5.0 | harbor.icurvestar.cn/docker.io/jimmidyson/configmap-reload:v0.5.0 |
| 3 | quay.io/brancz/kube-rbac-proxy:v0.14.2 | harbor.icurvestar.cn/quay.io/brancz/kube-rbac-proxy:v0.14.2 |
| 4 | quay.io/prometheus/alertmanager:v0.26.0 | harbor.icurvestar.cn/quay.io/prometheus/alertmanager:v0.26.0 |
| 5 | quay.io/prometheus/blackbox-exporter:v0.24.0 | harbor.icurvestar.cn/quay.io/prometheus/blackbox-exporter:v0.24.0 |
| 6 | quay.io/prometheus/node-exporter:v1.6.1 | harbor.icurvestar.cn/quay.io/prometheus/node-exporter:v1.6.1 |
| 7 | quay.io/prometheus/prometheus:v2.46.0 | harbor.icurvestar.cn/quay.io/prometheus/prometheus:v2.46.0 |
| 8 | quay.io/prometheus-operator/prometheus-config-reloader:v0.67.1 | harbor.icurvestar.cn/quay.io/prometheus-operator/prometheus-config-reloader:v0.67.1 |
| 9 | quay.io/prometheus-operator/prometheus-operator:v0.67.1 | harbor.icurvestar.cn/quay.io/prometheus-operator/prometheus-operator:v0.67.1 |
| 10 | registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2 | harbor.icurvestar.cn/registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2 |
| 11 | registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.11.1 | harbor.icurvestar.cn/registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.11.1 |
部署
3. 开始创建所有服务
# manifests/setup目录下有多个yaml配置文件
# kubectl create -f manifests/setup
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusagents.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/scrapeconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
namespace/monitoring created
kubectl create -f kube-prometheus-0.13.0/manifests/ --dry-run=client
# kubectl create -f manifests/
alertmanager.monitoring.coreos.com/main created
networkpolicy.networking.k8s.io/alertmanager-main created
poddisruptionbudget.policy/alertmanager-main created
prometheusrule.monitoring.coreos.com/alertmanager-main-rules created
secret/alertmanager-main created
service/alertmanager-main created
serviceaccount/alertmanager-main created
servicemonitor.monitoring.coreos.com/alertmanager-main created
clusterrole.rbac.authorization.k8s.io/blackbox-exporter created
clusterrolebinding.rbac.authorization.k8s.io/blackbox-exporter created
configmap/blackbox-exporter-configuration created
deployment.apps/blackbox-exporter created
networkpolicy.networking.k8s.io/blackbox-exporter created
service/blackbox-exporter created
serviceaccount/blackbox-exporter created
servicemonitor.monitoring.coreos.com/blackbox-exporter created
secret/grafana-config created
secret/grafana-datasources created
configmap/grafana-dashboard-alertmanager-overview created
configmap/grafana-dashboard-apiserver created
configmap/grafana-dashboard-cluster-total created
configmap/grafana-dashboard-controller-manager created
configmap/grafana-dashboard-grafana-overview created
configmap/grafana-dashboard-k8s-resources-cluster created
configmap/grafana-dashboard-k8s-resources-multicluster created
configmap/grafana-dashboard-k8s-resources-namespace created
configmap/grafana-dashboard-k8s-resources-node created
configmap/grafana-dashboard-k8s-resources-pod created
configmap/grafana-dashboard-k8s-resources-workload created
configmap/grafana-dashboard-k8s-resources-workloads-namespace created
configmap/grafana-dashboard-kubelet created
configmap/grafana-dashboard-namespace-by-pod created
configmap/grafana-dashboard-namespace-by-workload created
configmap/grafana-dashboard-node-cluster-rsrc-use created
configmap/grafana-dashboard-node-rsrc-use created
configmap/grafana-dashboard-nodes-darwin created
configmap/grafana-dashboard-nodes created
configmap/grafana-dashboard-persistentvolumesusage created
configmap/grafana-dashboard-pod-total created
configmap/grafana-dashboard-prometheus-remote-write created
configmap/grafana-dashboard-prometheus created
configmap/grafana-dashboard-proxy created
configmap/grafana-dashboard-scheduler created
configmap/grafana-dashboard-workload-total created
configmap/grafana-dashboards created
networkpolicy.networking.k8s.io/grafana created
prometheusrule.monitoring.coreos.com/grafana-rules created
service/grafana created
serviceaccount/grafana created
servicemonitor.monitoring.coreos.com/grafana created
prometheusrule.monitoring.coreos.com/kube-prometheus-rules created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
networkpolicy.networking.k8s.io/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kube-state-metrics-rules created
service/kube-state-metrics created
serviceaccount/kube-state-metrics created
servicemonitor.monitoring.coreos.com/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kubernetes-monitoring-rules created
servicemonitor.monitoring.coreos.com/kube-apiserver created
servicemonitor.monitoring.coreos.com/coredns created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
servicemonitor.monitoring.coreos.com/kube-scheduler created
servicemonitor.monitoring.coreos.com/kubelet created
clusterrole.rbac.authorization.k8s.io/node-exporter created
clusterrolebinding.rbac.authorization.k8s.io/node-exporter created
daemonset.apps/node-exporter created
networkpolicy.networking.k8s.io/node-exporter created
prometheusrule.monitoring.coreos.com/node-exporter-rules created
service/node-exporter created
serviceaccount/node-exporter created
servicemonitor.monitoring.coreos.com/node-exporter created
clusterrole.rbac.authorization.k8s.io/prometheus-k8s created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created
networkpolicy.networking.k8s.io/prometheus-k8s created
poddisruptionbudget.policy/prometheus-k8s created
prometheus.monitoring.coreos.com/k8s created
prometheusrule.monitoring.coreos.com/prometheus-k8s-prometheus-rules created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s-config created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
service/prometheus-k8s created
serviceaccount/prometheus-k8s created
servicemonitor.monitoring.coreos.com/prometheus-k8s created
clusterrole.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created
clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created
configmap/adapter-config created
deployment.apps/prometheus-adapter created
networkpolicy.networking.k8s.io/prometheus-adapter created
poddisruptionbudget.policy/prometheus-adapter created
rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created
service/prometheus-adapter created
serviceaccount/prometheus-adapter created
servicemonitor.monitoring.coreos.com/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
networkpolicy.networking.k8s.io/prometheus-operator created
prometheusrule.monitoring.coreos.com/prometheus-operator-rules created
service/prometheus-operator created
serviceaccount/prometheus-operator created
servicemonitor.monitoring.coreos.com/prometheus-operator created
Error from server (AlreadyExists): error when creating "manifests/prometheusAdapter-apiService.yaml": apiservices.apiregistration.k8s.io "v1beta1.metrics.k8s.io" already exists
Error from server (AlreadyExists): error when creating "manifests/prometheusAdapter-clusterRoleAggregatedMetricsReader.yaml": clusterroles.rbac.authorization.k8s.io "system:aggregated-metrics-reader" already exists
error parsing manifests/grafana-deployment.yaml: error converting YAML to JSON: yaml: line 33: mapping values are not allowed in this context
# 最后一个报错不正常,博哥没有
error parsing manifests/grafana-deployment.yaml: error converting YAML to JSON: yaml: line 33: mapping values are not allowed in this context
这个错误信息表明在解析Grafana部署的YAML文件时出现了问题,具体是在将YAML转换为JSON的过程中。错误位置在第33行,并且错误原因是“mapping values are not allowed in this context”,这通常意味着在YAML文件的这一行或者附近存在语法问题。
多了个images:
会创建命名空间 monitoring
过一会查看创建结果:
kubectl -n monitoring get all
kubectl -n monitoring get pod -w
# 附:清空上面部署的prometheus所有服务:
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup报错
# kubectl -n monitoring get all
NAME READY STATUS RESTARTS AGE
pod/prometheus-k8s-0 1/2 ImagePullBackOff 0 2m52s
pod/prometheus-k8s-1 1/2 ImagePullBackOff 0 2m51s
# kubectl -n monitoring describe pod prometheus-k8s-0
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 4m29s default-scheduler Successfully assigned monitoring/prometheus-k8s-0 to 10.0.1.203
Normal Pulling 4m7s kubelet Pulling image "easzlab.io.local:5000/prometheus-operator/prometheus-config-reloader:v0.67.1"
Normal Pulled 4m1s kubelet Successfully pulled image "easzlab.io.local:5000/prometheus-operator/prometheus-config-reloader:v0.67.1" in 6.799295747s (6.799309593s including waiting)
Normal Created 4m kubelet Created container init-config-reloader
Normal Started 4m kubelet Started container init-config-reloader
Normal Created 3m44s kubelet Created container config-reloader
Normal Pulled 3m44s kubelet Container image "easzlab.io.local:5000/prometheus-operator/prometheus-config-reloader:v0.67.1" already present on machine
Normal Started 3m40s kubelet Started container config-reloader
Warning Failed 3m1s (x3 over 3m44s) kubelet Failed to pull image "easzlab.io.local:5000/prometheus/prometheus:v2.46.0": rpc error: code = NotFound desc = failed to pull and unpack image "easzlab.io.local:5000/prometheus/prometheus:v2.46.0": failed to resolve reference "easzlab.io.local:5000/prometheus/prometheus:v2.46.0": easzlab.io.local:5000/prometheus/prometheus:v2.46.0: not found
Warning Failed 3m1s (x3 over 3m44s) kubelet Error: ErrImagePull
Normal BackOff 2m35s (x4 over 3m40s) kubelet Back-off pulling image "easzlab.io.local:5000/prometheus/prometheus:v2.46.0"
Warning Failed 2m35s (x4 over 3m40s) kubelet Error: ImagePullBackOff
Normal Pulling 2m20s (x4 over 3m44s) kubelet Pulling image "easzlab.io.local:5000/prometheus/prometheus:v2.46.0"
# docker images |grep prometheus/prometheus
easzlab.io.local:5000/prometheus/prometheus v2.46.0 3b907f5313b7 11 months ago 245MB
quay.io/prometheus/prometheus v2.46.0 3b907f5313b7 11 months ago 245MB
docker images |grep easzlab.io.local:5000/prometheus/prometheus:v2.46.0
# curl -X GET http://easzlab.io.local:5000/v2/prometheus/prometheus/tags/list
{"name":"prometheus/prometheus","tags":["v2.46.0"]}
push
kubectl -n monitoring delete pod prometheus-k8s-0
kubectl -n monitoring delete pod prometheus-k8s-1开始安装
kubectl create -f kube-prometheus-0.13.0/manifests/setup --dry-run=client -o yaml > manifests-setup.yaml
kubectl create -f kube-prometheus-0.13.0/manifests/ --dry-run=client -o yaml > manifests.yaml
3. 开始创建所有服务
# manifests/setup目录下有多个yaml配置文件
kubectl create -f manifests/setup
kubectl create -f manifests/
过一会查看创建结果:
kubectl -n monitoring get all
kubectl -n monitoring get pod -w
# 附:清空上面部署的prometheus所有服务:
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/blackbox-exporter 1/1 1 1 7m13s
deployment.apps/grafana 1/1 1 1 7m12s
deployment.apps/kube-state-metrics 1/1 1 1 7m11s
deployment.apps/prometheus-adapter 2/2 2 2 7m9s
deployment.apps/prometheus-operator 1/1 1 1 7m9s
NAME DESIRED CURRENT READY AGE
replicaset.apps/blackbox-exporter-759b8b4687 1 1 1 7m13s
replicaset.apps/grafana-7876655d94 1 1 1 7m11s
replicaset.apps/kube-state-metrics-7b8cd6cd4 1 1 1 7m11s
replicaset.apps/prometheus-adapter-fb66cfb9b 2 2 2 7m9s
replicaset.apps/prometheus-operator-7b5df886d6 1 1 1 7m9s减少alertmanager-main
# kubectl -n monitoring get pod -w -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-main-0 2/2 Running 0 5m41s 172.20.160.18 k8s-192-168-10-205 <none> <none>
alertmanager-main-1 2/2 Running 0 2m53s 172.20.5.149 k8s-192-168-10-204 <none> <none>
alertmanager-main-2 2/2 Running 0 2m53s 172.20.57.77 k8s-192-168-10-203 <none> <none>
# kubectl -n monitoring get alertmanager
NAME VERSION REPLICAS READY RECONCILED AVAILABLE AGE
main 0.26.0 3 3 True True 22m创建ingress
访问下prometheus的UI
# vim prometheus-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus
spec:
rules:
- host: prometheus.icurvestar.cn
http:
paths:
- backend:
service:
name: prometheus-k8s
port:
number: 9090
path: /
pathType: Prefixkubectl -n monitoring apply -f prometheus-ingress.yamlgrafana ingress创建
# vim grafana-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: grafana
spec:
rules:
- host: grafana..icurvestar.cn
http:
paths:
- backend:
service:
name: grafana
port:
number: 3000
path: /
pathType: Prefixkubectl -n monitoring apply -f grafana-ingress.yaml问题:
打开prometheus.boge.com 和grafana.boge.com 显示 502
# kubectl -n monitoring exec -it prometheus-k8s-0 -- sh
/prometheus $ netstat -tulnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 :::8080 :::* LISTEN -
tcp 0 0 :::9090 :::* LISTEN 1/prometheus
/home $ wget 127.0.0.1:9090
Connecting to 127.0.0.1:9090 (127.0.0.1:9090)
wget: can't open 'index.html': Read-only file system
telnet 127.0.0.1 9090
说明本地访问是正常的
在master节点直接访问其他命名空间的svc也是没问题的
解决↓注意:删除自带的网络策略(新版),否则访问服务都会被阻塞
https://github.com/prometheus-operator/kube-prometheus/issues/1763#issuecomment-1139553506
# kubectl -n monitoring delete networkpolicies.networking.k8s.io --all
networkpolicy.networking.k8s.io "alertmanager-main" deleted
networkpolicy.networking.k8s.io "blackbox-exporter" deleted
networkpolicy.networking.k8s.io "grafana" deleted
networkpolicy.networking.k8s.io "kube-state-metrics" deleted
networkpolicy.networking.k8s.io "node-exporter" deleted
networkpolicy.networking.k8s.io "prometheus-adapter" deleted
networkpolicy.networking.k8s.io "prometheus-k8s" deleted
networkpolicy.networking.k8s.io "prometheus-operator" deleted(三) 修复核心服务监控
访问prometheus后台,点击上方菜单栏Status — Targets ,我们发现kube-controller-manager和kube-scheduler未发现
接下来我们解决下这一个碰到的问题吧
Status—Targets一些在监听的服务
# 这里我们发现这两服务监听的IP是0.0.0.0 正常
# ss -tlnp|egrep 'controller|schedule'
LISTEN 0 32768 *:10257 *:* users:(("kube-controller",pid=3528,fd=3))
LISTEN 0 32768 *:10259 *:* users:(("kube-scheduler",pid=837,fd=3))
# ps -aux | grep 17319 | grep -v grep
root 17319 0.2 2.0 1339280 81844 ? Ssl 10:45 1:39 /opt/kube/bin/kube-controller-manager
root@k8s-192-168-10-203:~# ss -tlnp|egrep 'controller|schedule'
LISTEN 0 32768 *:9094 *:* users:(("kube-controller",pid=1898,fd=10))
# ps -aux | grep 1898 | grep -v grep
999 1898 0.1 1.3 2022276 54900 ? Ssl 21:29 0:02 /usr/bin/kube-controllers# curl https://10.0.1.201:10257/metrics
curl: (60) SSL certificate problem: self-signed certificate in certificate chain
More details here: https://curl.se/docs/sslcerts.html
curl failed to verify the legitimacy of the server and therefore could not
establish a secure connection to it. To learn more about this situation and
how to fix it, please visit the web page mentioned above.
# curl -k https://10.0.1.201:10257/metrics
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "forbidden: User \"system:anonymous\" cannot get path \"/metrics\"",
"reason": "Forbidden",
"details": {},
"code": 403
}
403拒绝,要证书
systemctl status kube-controller-manager.service部署一个servicemonitor能把相应的service的指标暴露给prometheus-server
现在有kube-controller-manager和kube-scheduler的servicemonitor但是没有service就识别不到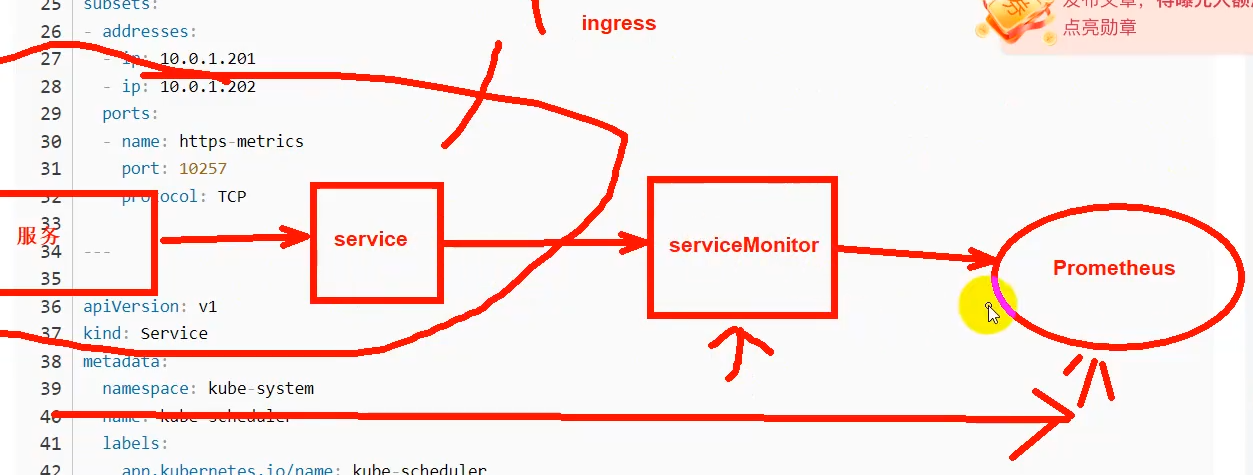
然后因为K8s的这两上核心组件我们是以二进制形式部署的,为了能让K8s上的prometheus能发现,我们需要来创建相应的service和endpoints来将其关联起来
Endpoints和Service的名称要一样的
注意:我们需要将endpoints里面的NODE IP换成我们实际情况的
kubectl get all --all-namespaces -l app.kubernetes.io/name=kube-controller-manager
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
app.kubernetes.io/name: kube-controller-manager
spec:
type: ClusterIP
clusterIP: None
ports:
- name: https-metrics
port: 10257
targetPort: 10257
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
app.kubernetes.io/name: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.10.201
- ip: 192.168.10.202
ports:
- name: https-metrics
port: 10257
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
app.kubernetes.io/name: kube-scheduler
spec:
type: ClusterIP
clusterIP: None
ports:
- name: https-metrics
port: 10259
targetPort: 10259
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
app.kubernetes.io/name: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.10.201
- ip: 192.168.10.202
ports:
- name: https-metrics
port: 10259
protocol: TCP将上面的yaml配置保存为repair-prometheus.yaml,然后创建它
# kubectl apply -f repair-prometheus.yaml
service/kube-controller-manager created
endpoints/kube-controller-manager created
service/kube-scheduler created
endpoints/kube-scheduler created创建完成后确认下
# kubectl -n kube-system get svc |egrep 'controller|scheduler'
kube-controller-manager ClusterIP None <none> 10257/TCP 14s
kube-scheduler ClusterIP None <none> 10259/TCP 14s然后再返回prometheus UI处,耐心等待一会,就能看到已经被发现了
serviceMonitor/monitoring/kube-controller-manager/0 (2/2 up)
serviceMonitor/monitoring/kube-scheduler/0 (2/2 up)云平台的非自建K8S的一些核心服务相当于黑盒
新版的可能会显示
旧版可能会识别不到或者显示警告、错误 可以忽略它
后面带大家怎么屏蔽掉报警,自己写一个普罗米修斯报警接收、发生服务去做一些关键词过滤(四) 监控ETCD集群
可以先做prometheus和grafana的持久化存储
这节课我们利用prometheus来监控二进制部署的ETCD集群。
作为K8s所有资源存储的关键服务ETCD,我们也有必要把它给监控起来,正好借这个机会,完整的演示一次利用Prometheus来监控非K8s集群服务的步骤
在前面部署K8s集群的时候,我们是用二进制的方式部署的ETCD集群,并且利用自签证书来配置访问ETCD,正如前面所说,现在关键的服务基本都会留有指标metrics接口支持prometheus的监控,利用下面命令,我们可以看到ETCD都暴露出了哪些监控指标出来
# ezctl list
2024-08-30 22:39:33 INFO list of managed clusters:
==> cluster 1: icurvestar-test-cn (current)
curl --cacert /etc/kubernetes/ssl/ca.pem --cert /etc/kubeasz/clusters/icurvestar-test-cn/ssl/etcd.pem --key /etc/kubeasz/clusters/icurvestar-test-cn/ssl/etcd-key.pem https://192.168.10.201:2379/metrics上面查看没问题后,接下来我们开始进行配置使ETCD能被prometheus发现并监控
# 首先把ETCD的证书创建为secret
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/kubeasz/clusters/icurvestar-test-cn/ssl/etcd.pem --from-file=/etc/kubeasz/clusters/icurvestar-test-cn/ssl/etcd-key.pem --from-file=/etc/kubeasz/clusters/icurvestar-test-cn/ssl/ca.pem
# 接着在prometheus里面引用这个secrets
kubectl -n monitoring edit prometheus k8s
spec:
...
secrets:
- etcd-certs
# 保存退出后,prometheus会自动重启服务pod以加载这个secret配置,过一会,我们进pod来查看下是不是已经加载到ETCD的证书了
# kubectl -n monitoring exec -it prometheus-k8s-0 -c prometheus -- sh
/prometheus $ ls -lh /etc/prometheus/secrets/etcd-certs/
total 0
lrwxrwxrwx 1 root 2000 13 Jun 23 15:30 ca.pem -> ..data/ca.pem
lrwxrwxrwx 1 root 2000 19 Jun 23 15:30 etcd-key.pem -> ..data/etcd-key.pem
lrwxrwxrwx 1 root 2000 15 Jun 23 15:30 etcd.pem -> ..data/etcd.pem接下来准备创建service、endpoints以及ServiceMonitor的yaml配置
注意替换下面的NODE节点IP为实际ETCD所在NODE内网IP
# vim prometheus-etcd.yaml
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: api
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 192.168.10.201
- ip: 192.168.10.202
- ip: 192.168.10.203
ports:
- name: api
port: 2379
protocol: TCP
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd-k8s
spec:
jobLabel: k8s-app
endpoints:
- port: api
interval: 30s # 抓取频率,可自行调节
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-certs/ca.pem
certFile: /etc/prometheus/secrets/etcd-certs/etcd.pem
keyFile: /etc/prometheus/secrets/etcd-certs/etcd-key.pem
#use insecureSkipVerify only if you cannot use a Subject Alternative Name
insecureSkipVerify: true
selector:
# svc的lable
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames:
- monitoring开始创建上面的资源
# kubectl apply -f prometheus-etcd.yaml
service/etcd-k8s created
endpoints/etcd-k8s created
servicemonitor.monitoring.coreos.com/etcd-k8s created过一会,就可以在prometheus UI上面看到ETCD集群被监控了
serviceMonitor/monitoring/etcd-k8s/0 (3/3 up)接下来我们用grafana来展示被监控的ETCD指标
1. 在grafana官网模板中心搜索etcd,下载这个json格式的模板文件
https://grafana.com/grafana/dashboards/3070-etcd/
2.然后打开自己先部署的grafana首页,
icurvestar icurvestar@666
点击左上边菜单栏HOME --- Administration --- Data sources --- Add data source --- 选择 Prometheus
查看prometheus的详细地址 并编辑进去保存:
# kubectl -n monitoring get secrets grafana-datasources -o yaml
apiVersion: v1
data:
datasources.yaml: ewogICAgImFwaVZlcnNpb24iOiAxLAogICAgImRhdGFzb3VyY2VzIjogWwogICAgICAgIHsKICAgICAgICAgICAgImFjY2VzcyI6ICJwcm94eSIsCiAgICAgICAgICAgICJlZGl0YWJsZSI6IGZhbHNlLAogICAgICAgICAgICAibmFtZSI6ICJwcm9tZXRoZXVzIiwKICAgICAgICAgICAgIm9yZ0lkIjogMSwKICAgICAgICAgICAgInR5cGUiOiAicHJvbWV0aGV1cyIsCiAgICAgICAgICAgICJ1cmwiOiAiaHR0cDovL3Byb21ldGhldXMtazhzLm1vbml0b3Jpbmcuc3ZjOjkwOTAiLAogICAgICAgICAgICAidmVyc2lvbiI6IDEKICAgICAgICB9CiAgICBdCn0=
kind: Secret
metadata:
creationTimestamp: "2024-08-30T13:35:45Z"
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 9.5.3
name: grafana-datasources
namespace: monitoring
resourceVersion: "76240"
uid: b49b7e3b-64d2-446c-be12-e0d3f0b93bcb
type: Opaque
解码
# echo "ewogICAgImFwaVZlcnNpb24iOiAxLAogICAgImRhdGFzb3VyY2VzIjogWwogICAgICAgIHsKICAgICAgICAgICAgImFjY2VzcyI6ICJwcm94eSIsCiAgICAgICAgICAgICJlZGl0YWJsZSI6IGZhbHNlLAogICAgICAgICAgICAibmFtZSI6ICJwcm9tZXRoZXVzIiwKICAgICAgICAgICAgIm9yZ0lkIjogMSwKICAgICAgICAgICAgInR5cGUiOiAicHJvbWV0aGV1cyIsCiAgICAgICAgICAgICJ1cmwiOiAiaHR0cDovL3Byb21ldGhldXMtazhzLm1vbml0b3Jpbmcuc3ZjOjkwOTAiLAogICAgICAgICAgICAidmVyc2lvbiI6IDEKICAgICAgICB9CiAgICBdCn0=" | base64 --decode
{
"apiVersion": 1,
"datasources": [
{
"access": "proxy",
"editable": false,
"name": "prometheus",
"orgId": 1,
"type": "prometheus",
"url": "http://prometheus-k8s.monitoring.svc:9090",
"version": 1
}
]
}
http://prometheus-k8s.monitoring.svc:9090
下滑选择保存测试
再点击右上角 +^ Import dashboard ---
点击Upload .json File 按钮,上传上面下载好的json文件 3070_rev3.json,
选择刚刚的 prometheus-1
点击Import,即可显示etcd集群的图形监控信息Etcd has a leader?
Edit
Metrics browser
max(etcd_server_has_leader)
把max(etcd_server_has_leader)复制到Prometheus的Graph执行
# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
10.0.1.201 251m 6% 3153Mi 88%
10.0.1.202 154m 7% 1741Mi 48%
10.0.1.203 284m 14% 3888Mi 69%
10.0.1.204 156m 7% 2816Mi 78%
# 其实node1只用了1.95/3.79G(五) 监控ingress controller
我们前面部署过ingress-nginx,这个是整个K8s上所有服务的流量入口组件很关键,因此把它的metrics指标收集到prometheus来做好相关监控至关重要,因为前面ingress-nginx服务是以daemonset形式部署的,并且映射了自己的端口到宿主机上,那么我可以直接用pod运行NODE上的IP来看下metrics
# kubectl -n kube-system get pod -o wide|grep nginx-ingress
# kubectl -n ingress-controller get pod -o wide|grep nginx-ingress
nginx-ingress-controller-bnxfn 1/1 Running 3 (13h ago) 2d 192.168.10.201 k8s-192-168-10-201 <none> <none>
nginx-ingress-controller-t8mgf 1/1 Running 6 (121m ago) 2d 192.168.10.202 k8s-192-168-10-202 <none> <none>
# 开启metrics指标
# kubectl -n kube-system edit ds nginx-ingress-controller
# kubectl -n ingress-controller edit ds nginx-ingress-controller
# 搜索 enable-metrics , 找到 - --enable-metrics= 设置为 true
# 如果业务上不需要监控指标,可以关闭,减少资源损耗
# curl 192.168.10.201:10254/metrics
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.9813e-05
go_gc_duration_seconds{quantile="0.25"} 7.174e-05
go_gc_duration_seconds{quantile="0.5"} 0.000131089
go_gc_duration_seconds{quantile="0.75"} 0.000511873
go_gc_duration_seconds{quantile="1"} 0.20378584
go_gc_duration_seconds_sum 0.472987359
go_gc_duration_seconds_count 211
......创建 servicemonitor配置让prometheus能发现ingress-nginx的metrics
# vim ingress-nginx-servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: ingress-nginx
name: nginx-ingress-scraping
namespace: ingress-controller
spec:
endpoints:
- interval: 30s
path: /metrics
# port name 在svc里定义
port: metrics
jobLabel: app
namespaceSelector:
matchNames:
# ingress controller的命名空间
- ingress-controller
selector:
matchLabels:
app: ingress-nginx该
ServiceMonitor的作用是监控命名空间ingress-controller中标签为app: ingress-nginx的服务,定期访问其/metrics路径
kubectl -n ingress-controller get service -l app=ingress-nginx创建它
# kubectl apply -f ingress-nginx-servicemonitor.yaml
servicemonitor.monitoring.coreos.com/nginx-ingress-scraping created
# kubectl -n ingress-controller get servicemonitors.monitoring.coreos.com
NAME AGE
nginx-ingress-scraping 43s
kubectl -n test-ingress-controller describe servicemonitors.monitoring.coreos.com etcd-k8s
kubectl -n monitoring get servicemonitors.monitoring.coreos.com
# kubectl delete -f ingress-nginx-servicemonitor.yaml
kubectl -n ingress-controller get svc
kubectl -n ingress-controller describe svc nginx-ingress-lb
kubectl -n ingress-controller edit svc nginx-ingress-lb
kubectl get endpoints -n ingress-controller等个2-3分钟再到prometheus UI上看下,发现已经有了
serviceMonitor/kube-system/nginx-ingress-scraping/0 (1/1 up)下载grafana模板导入使用
https://grafana.com/grafana/dashboards/14314-kubernetes-nginx-ingress-controller-nextgen-devops-nirvana/
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
creationTimestamp: "2024-08-30T13:35:48Z"
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.46.0
name: prometheus-k8s
resourceVersion: "76410"
uid: 506de035-e87c-441c-b1ca-3991c56084e3
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- getapiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- getapiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
- configmaps
- nodes/metrics
verbs:
- get
- list
- watch
- nonResourceURLs:
- /metrics
verbs:
- get(六) 持久化存储
prometheus和grafana的持久化存储
prometheus配置持久化数据
# 注意这下面的statefulset服务就是我们需要做数据持久化的地方
# kubectl -n monitoring get statefulset,pod|grep prometheus-k8s
statefulset.apps/prometheus-k8s 2/2 64m
pod/prometheus-k8s-0 2/2 Running 0 51s
pod/prometheus-k8s-1 2/2 Running 0 69s
# 看下我们之前准备的StorageClass动态存储
# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-icurvestar nfs-provisioner-01 Retain Immediate false 47h
# 准备prometheus持久化的pvc配置
# kubectl -n monitoring edit prometheus k8s
spec:
......
storage:
volumeClaimTemplate:
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs-icurvestar"
resources:
requests:
storage: 1Gi # 根据情况加大,50G,100G
# 上面修改保存退出后,过一会我们查看下pvc创建情况,以及pod内的数据挂载情况
# kubectl -n monitoring get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-k8s-db-prometheus-k8s-0 Bound pvc-08c01fd9-f18d-45ca-99fd-aaffdd1f4aa6 1Gi RWO nfs-boge 6s
prometheus-k8s-db-prometheus-k8s-1 Bound pvc-446dea20-0eff-452a-9c40-23b2acf7fd95 1Gi RWO nfs-boge 6s
statefulset.apps/prometheus-k8s 里原来:
spec:
containers:
volumeMounts:
- mountPath: /prometheus
name: prometheus-k8s-db
volumes:
- emptyDir: {}
name: prometheus-k8s-db
更新后
volumeMounts:
- mountPath: /prometheus
name: prometheus-k8s-db
subPath: prometheus-db
volumeClaimTemplates:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
creationTimestamp: null
name: prometheus-k8s-db
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: nfs-icurvestar
volumeMode: Filesystem
status:
phase: Pending
# kubectl -n monitoring exec -it prometheus-k8s-0 -c prometheus -- sh
/prometheus $ df -Th
......
1192.168.10.201:/nfs_dir/monitoring-prometheus-k8s-db-prometheus-k8s-0-pvc-a13c4c73-4082-4979-a38b-b22401a5d648/prometheus-db
nfs4 191.9G 22.6G 159.5G 12% /prometheus
kubectl -n monitoring delete pod prometheus-k8s-0 && kubectl -n monitoring delete pvc prometheus-k8s-db-prometheus-k8s-0 && kubectl -n monitoring delete pod prometheus-k8s-1 && kubectl -n monitoring delete pvc prometheus-k8s-db-prometheus-k8s-1grafana配置持久化存储
# 保存pvc为grafana-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: grafana
namespace: monitoring
spec:
storageClassName: nfs-icurvestar
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi # 相对普罗米修斯需求不大,存放模板,分配个5G,10G,20G# 开始创建pvc
# kubectl apply -f grafana-pvc.yaml
kubectl -n monitoring get pod
# kubectl -n monitoring delete pod grafana-676df8577b-jcdkt && kubectl delete -f grafana-pvc.yaml
# 看下创建的pvc
# kubectl -n monitoring get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
grafana Bound pvc-b947082f-9648-42c0-8a1b-c4607857ad40 1Gi RWX nfs-icurvestar 19s
prometheus-k8s-db-prometheus-k8s-0 Bound pvc-a13c4c73-4082-4979-a38b-b22401a5d648 1Gi RWO nfs-icurvestar 6m54s
prometheus-k8s-db-prometheus-k8s-1 Bound pvc-bd54f333-be0e-4d64-9b2c-779f6a9d53fb 1Gi RWO nfs-icurvestar 6m54s
# 编辑grafana的deployment资源配置
# kubectl -n monitoring edit deployments.apps grafana
# 旧的配置
volumes:
- emptyDir: {}
name: grafana-storage
# 替换成新的配置
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana
# 同时加入下面的env环境变量,将登陆密码进行固定修改
spec:
containers:
......
- image:
env:
- name: GF_SECURITY_ADMIN_USER
value: icurvestar
- name: GF_SECURITY_ADMIN_PASSWORD
value: icurvestar@666
修改pvc和环境变量的账户密码要同时进行。如果先修改pvc再修改环境变量,要删除pvc重新创建pvc
# 过一会,等grafana重启完成后,用上面的新密码进行登陆
# kubectl -n monitoring get pod -w|grep grafana
grafana-5698bf94f4-prbr2 0/1 Running 0 3s
grafana-5698bf94f4-prbr2 1/1 Running 0 4s
# 因为先前的数据并未持久化,所以会发现先导入的ETCD模板已消失,这时重新再导入一次,后面重启也不会丢了
数据源
http://prometheus-k8s.monitoring.svc:9090
svc可以省略,grafana跟promethues一个命名空间,连monitoring都可以省略
http://prometheus-k8s:9090为什么把k8s配置 spec:
automountServiceAccountToken: false
containers:
- image: easzlab.io.local:5000/grafana/grafana:9.5.3
imagePullPolicy: IfNotPresent
name: grafana
ports:
- containerPort: 3000
name: http
protocol: TCP
改为
spec:
automountServiceAccountToken: false
containers:
- image: easzlab.io.local:5000/grafana/grafana:9.5.3
imagePullPolicy: IfNotPresent
name: grafana
env:
- name: GF_SECURITY_ADMIN_USER
value: boge
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
ports:
- containerPort: 3000
name: http
protocol: TCP
结果是变成了
spec:
automountServiceAccountToken: false
containers:
- env:
- name: GF_SECURITY_ADMIN_USER
value: boge
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
image: easzlab.io.local:5000/grafana/grafana:9.5.3
imagePullPolicy: IfNotPresent
name: grafana
ports:
- containerPort: 3000
name: http
protocol: TCP
变化前后env和image始终都是平级的
这个顺序的变化对 Kubernetes 部署本身没有影响,因为 YAML 的键值对顺序在解析时并不重要。Kubernetes 会正确地解析和应用这些配置,所以只要属性的值是正确的,顺序的改变不会影响应用程序的实际行为。kubectl -n monitoring exec -it grafana-676df8577b-jcdkt -- sh
env
GF_SECURITY_ADMIN_PASSWORD=admin321
GF_SECURITY_ADMIN_USER=boge(七) promql语法
对于怎么使用promql语法,也教了大家取巧的方式通过现有成熟的grafana模板,学习其中监控语法的使用,但是却是知其然而不知其所以然。
尤其是这个promql语法,想着怎么更好地让大家理解掌握它,想起来自己在几年前初学prometheus的时候,有幸找到了一些优秀的文章,在使用prometheus就没有走多少弯路,那这节课回归理论性的内容,给大家分享些这些优秀的内容。
https://yunlzheng.gitbook.io/prometheus-book
https://github.com/yunlzheng/prometheus-book
如果上面的内容找不开或很慢,那么可以通过下面的github国内镜像站来打开查看
https://githubfast.com/yunlzheng/prometheus-book
(八) golang暴露prometheus指标
从这节课开始,博哥计划引入golang(简称go)语言开发的一些内容,没有接触过go语言的同学也不用慌,我会尽量以一个新人的角度,去把这些go开发的内容讲得通俗一些。这节课还是继续 prometheus监控相关的内容,博哥带大家用go语言开发一个简单的http服务并暴露相应的prometheus指标。
首先电脑上需要安装好go语言,下载链接(选择相应的系统安装包):
https://golang.google.cn/dl/
然后安装好vscode这个编程IDE工具:
https://code.visualstudio.com/
配置好vscode里面go的相关插件,可以参考下这个文档:
https://zhuanlan.zhihu.com/p/320343679
Code Runner插件
我来先准备写一个简单的http服务扮演我们的业务服务角色
翻译自:https://prometheus.io/docs/tutorials/instrumenting_http_server_in_go/
// 入口包
package main
import (
// 打印依赖
"fmt"
"net/http"
)
// 函数
func ping(w http.ResponseWriter, req *http.Request){
fmt.Fprintf(w,"pong")
}
// 执行入口
func main() {
http.HandleFunc("/ping",ping)
业务端口
http.ListenAndServe(":8090", nil)
}// 入口包
package main
import (
"fmt"
"net/http"
)
func ping(w http.ResponseWriter, req *http.Request){
fmt.Fprintf(w,"pong")
}
func main() {
http.HandleFunc("/ping",ping)
http.ListenAndServe(":8090", nil)
}运行测试下,确保服务访问正常
然后我们准备创建一个 Prometheus counter计数器(只增不减),来记录请求数
var pingCounter = prometheus.NewCounter(
prometheus.CounterOpts{
Name: "ping_request_count",
Help: "No of request handled by Ping handler",
},
)接着我们在ping函数里面加入 pingCounter.Inc()来引用这个计数器
func ping(w http.ResponseWriter, req *http.Request) {
pingCounter.Inc()
fmt.Fprintf(w, "pong")
}然后将计数器注册到 Default Register 并公开指标
func main() {
prometheus.MustRegister(pingCounter)
http.HandleFunc("/ping", ping)
http.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":8090", nil)
}最终完整代码如下:
package main
import (
"fmt"
"net/http"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var pingCounter = prometheus.NewCounter(
prometheus.CounterOpts{
Name: "ping_request_count",
Help: "No of request handled by Ping handler",
},
)
func ping(w http.ResponseWriter, req *http.Request) {
pingCounter.Inc()
fmt.Fprintf(w, "pong")
}
func main() {
prometheus.MustRegister(pingCounter)
http.HandleFunc("/ping", ping)
http.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":8090", nil)
}// 导入必需的包
package main
import (
"fmt" // 用于格式化输入输出
"net/http" // 提供HTTP客户端和服务端实现
"github.com/prometheus/client_golang/prometheus" // Prometheus客户端库
"github.com/prometheus/client_golang/prometheus/promhttp" // Prometheus的HTTP处理函数
)
// 定义一个新的计数器来记录/ping的请求数量
var pingCounter = prometheus.NewCounter(
prometheus.CounterOpts{ // 配置计数器选项
Name: "ping_request_count", // 计数器的唯一名称
Help: "Number of requests handled by the Ping handler", // 计数器的帮助说明
},
)
// ping 处理函数,响应/ping 的HTTP请求
func ping(w http.ResponseWriter, req *http.Request) {
pingCounter.Inc() // 每次请求时增加计数器的值
fmt.Fprintf(w, "pong") // 向客户端响应 "pong"
}
// 主函数,程序入口
func main() {
// 注册pingCounter到Prometheus的默认注册表
prometheus.MustRegister(pingCounter)
// 设置HTTP路由,当访问/ping时调用ping函数处理
http.HandleFunc("/ping", ping)
// 设置/metrics路由,用于暴露Prometheus监控指标
http.Handle("/metrics", promhttp.Handler())
// 启动HTTP服务器,监听8090端口
http.ListenAndServe(":8090", nil)
}我们准备来运行它
# 初始化包管理
go mod init prometheus
# 用国内加速代理下载包
export GOPROXY=https://goproxy.cn
# 更新依赖包
go mod tidy
# 运行服务
go run server.go
go run main.goD:\Code\VSCode_Code\go\workspace\prometheus>go mod init prometheus
go: creating new go.mod: module prometheus
go: to add module requirements and sums:
go mod tidy
D:\Code\VSCode_Code\go\workspace\prometheus>go mod tidy
go: finding module for package github.com/prometheus/client_golang/prometheus/promhttp
go: finding module for package github.com/prometheus/client_golang/prometheus
go: found github.com/prometheus/client_golang/prometheus in github.com/prometheus/client_golang v1.19.1
go: found github.com/prometheus/client_golang/prometheus/promhttp in github.com/prometheus/client_golang v1.19.1查看暴露的指标
http://127.0.0.1:8090/metrics
搜索ping_request_count
增加一些请求数
http://127.0.0.1:8090/ping
# HELP ping_request_count No of request handled by Ping handler
# TYPE ping_request_count counter
ping_request_count 9这里我们可以修改prometheus的配置,来监控我们自定义的这个服务
global:
scrape_interval: 15s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ["localhost:9090"]
- job_name: simple_server
static_configs:
# 二进制 非容器运行的引用
- targets: ["localhost:8090"]或者也可以参照博哥之前的课程,用serviceMonitor来暴露指标
(九) webhook报警
部署日志清洗转发工具
早期我们经常用邮箱接收报警邮件,但是报警不及时,而且目前各云平台对邮件发送限制还比较严格,所以目前在生产中用得更为多的是基于webhook来转发报警内容到企业中用的聊天工具中,比如钉钉、企业微信、飞书等。
prometheus的报警组件是Alertmanager,它支持自定义webhook的方式来接受它发出的报警,它发出的日志json字段比较多,我们需要根据需要接收的app来做相应的日志清洗转发
这里博哥将用golang结合Gin网络框架来编写一个日志清洗转发工具,分别对这几种常用的报警方式作详细的说明及实战,源码的分享计划放入golang语言开发讲解课程里面,这样大家更容易接受。
https://github.com/bogeit/LearnK8s/tree/main/2023/boge-webhook
我们先制作好镜像,并上传到我们自己的私有仓库Harbor里面
# 使用alpine:3.18作为基础镜像
FROM alpine:3.18
# 设置镜像维护者信息
MAINTAINER Boge <github.com/bogeit>
# 设置环境变量 TZ 为 "Asia/Shanghai"
ENV TZ "Asia/Shanghai"
# 修改Alpine Linux的包管理器仓库为阿里云镜像站
# 安装curl、tzdata和ca-certificates软件包
# 将时区设置为Asia/Shanghai
# 升级已安装的软件包
# 清理apk缓存
RUN sed -ri 's+dl-cdn.alpinelinux.org+mirrors.aliyun.com+g' /etc/apk/repositories \
&& apk add --no-cache curl tzdata ca-certificates \
&& cp -f /usr/share/zoneinfo/Asia/Shanghai /etc/localtime \
&& apk upgrade \
&& rm -rf /var/cache/apk/*
# 将本地文件mycli复制到容器中的/usr/local/bin/目录下
COPY mycli /usr/local/bin/
# 给/usr/local/bin/mycli文件添加可执行权限
RUN chmod +x /usr/local/bin/mycli
# 设置容器的入口点为mycli,并传入参数"-h"
ENTRYPOINT ["mycli"]
CMD ["-h"]# 将上面代码仓库文件内容下载到目录
# 确认文件是否在当前目录
ls -l Dockerfile mycli
# 构建镜像
docker build -t harbor.icurvestar.cn/boge/alertmanaer-webhook:1.0 .
# 上传镜像
docker push harbor.icurvestar.cn/boge/alertmanaer-webhook:1.0
# 创建harbor私有仓库密钥,用于拉取私有镜像
# 在Kubernetes集群中的命名空间(namespace)monitoring中创建一个名为boge-secret的Docker仓库密钥(docker-registry secret)
kubectl -n monitoring create secret docker-registry icurvestar-harbor-secret --docker-server=harbor.icurvestar.cn --docker-username=icurvestar --docker-password=icurvestar@666 --docker-email=admin@icurvestar.cn# docker build -t harbor.boge.com/product/alertmanaer-webhook:1.0 .
DEPRECATED: The legacy builder is deprecated and will be removed in a future release.
Install the buildx component to build images with BuildKit:
https://docs.docker.com/go/buildx/
Sending build context to Docker daemon 3.916MB
Step 1/8 : FROM alpine:3.18
3.18: Pulling from library/alpine
73baa7ef167e: Pull complete
Digest: sha256:1875c923b73448b558132e7d4a44b815d078779ed7a73f76209c6372de95ea8d
Status: Downloaded newer image for alpine:3.18
---> 8fd7cac70a4a
Step 2/8 : MAINTAINER Boge <github.com/bogeit>
---> Running in 76a4b9752f37
Removing intermediate container 76a4b9752f37
---> bc0ae5f6090d
Step 3/8 : ENV TZ "Asia/Shanghai"
---> Running in 0edc569813ce
Removing intermediate container 0edc569813ce
---> cd2450689a9a
Step 4/8 : RUN sed -ri 's+dl-cdn.alpinelinux.org+mirrors.aliyun.com+g' /etc/apk/repositories && apk add --no-cache curl tzdata ca-certificates && cp -f /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && apk upgrade && rm -rf /var/cache/apk/*
---> Running in 82394b63f05c
fetch https://mirrors.aliyun.com/alpine/v3.18/main/x86_64/APKINDEX.tar.gz
fetch https://mirrors.aliyun.com/alpine/v3.18/community/x86_64/APKINDEX.tar.gz
(1/8) Installing ca-certificates (20240226-r0)
(2/8) Installing brotli-libs (1.0.9-r14)
(3/8) Installing libunistring (1.1-r1)
(4/8) Installing libidn2 (2.3.4-r1)
(5/8) Installing nghttp2-libs (1.57.0-r0)
(6/8) Installing libcurl (8.5.0-r0)
(7/8) Installing curl (8.5.0-r0)
(8/8) Installing tzdata (2024a-r0)
Executing busybox-1.36.1-r7.trigger
Executing ca-certificates-20240226-r0.trigger
OK: 15 MiB in 23 packages
fetch https://mirrors.aliyun.com/alpine/v3.18/main/x86_64/APKINDEX.tar.gz
fetch https://mirrors.aliyun.com/alpine/v3.18/community/x86_64/APKINDEX.tar.gz
OK: 15 MiB in 23 packages
Removing intermediate container 82394b63f05c
---> 751a5dac9da1
Step 5/8 : COPY mycli /usr/local/bin/
---> c28ffe02c6ce
Step 6/8 : RUN chmod +x /usr/local/bin/mycli
---> Running in 773c8b135e53
Removing intermediate container 773c8b135e53
---> a48e3d438f06
Step 7/8 : ENTRYPOINT ["mycli"]
---> Running in 3f10f415ed3c
Removing intermediate container 3f10f415ed3c
---> 72d7b8fb0c33
Step 8/8 : CMD ["-h"]
---> Running in 86c1339b5910
Removing intermediate container 86c1339b5910
---> 3a2bec77b57f
Successfully built 3a2bec77b57f
Successfully tagged harbor.boge.com/product/alertmanaer-webhook:1.0
# docker push harbor.boge.com/product/alertmanaer-webhook:1.0
The push refers to repository [harbor.boge.com/product/alertmanaer-webhook]
d7de58021090: Pushed
2ea2b53cb4e0: Pushed
c2c46528e4ae: Pushed
63ec0bd56cf3: Pushed
1.0: digest: sha256:5d1e904c6537a6f9bcee1d5c6456bcd1f2b4b31f6c5dae7f0dbdf6e8f3af7ea7 size: 1161将构建好的后端转发服务部署到K8S上面
先修改alertmanaer-webhook.yaml
kind: Deployment
metadata:
name: alertmanaer-dingtalk-dp
spec:
spec:
containers:
- name: alertmanaer-webhook
image: harbor.boge.com/product/alertmanaer-webhook:1.0
args:
- web
- "https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxxxxxxxxxxxxx"
- "9999"
- 自定义关键词 (不知道)
- IP 地址(没有公网ip)
- 加签
kubectl -n monitoring apply -f alertmanaer-webhook.yaml
# 如果出现镜像拉取失败问题,注意看当前pod运行的节点,上面需要添加私有仓库的本地hosts
# vim /etc/hosts
10.0.1.201 easzlab.io.local harbor.boge.com
# kubectl -n monitoring get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanaer-dingtalk-svc ClusterIP 10.68.233.136 <none> 80/TCP 32s
# curl 10.68.233.136/status
{"msg":"ok"}
# 指定后端转发服务的svc地址,发个post请求看看服务是否正常
curl -X POST -H 'Content-type: application/json' -d '{"name": "boge","titlea": "'"$(id)"'", "texta": "'"$(whoami)-$(hostname)"'"}' 10.68.233.136/b01bdc063/boge/getjson
# /getjson接口接收完整的报警数据
# kubectl -n monitoring logs alertmanaer-dingtalk-dp-89cfd9cd6-n57dh
[GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET /status --> mycli/libs.MyWebServer.func1 (3 handlers)
[GIN-debug] POST /b01bdc063/boge/getjson --> mycli/libs.MyWebServer.func2 (3 handlers)
[GIN-debug] POST /7332f19/prometheus/dingtalk --> mycli/libs.MyWebServer.func3 (3 handlers)
[GIN-debug] POST /1bdc0637/prometheus/feishu --> mycli/libs.MyWebServer.func4 (3 handlers)
[GIN-debug] POST /5e00fc1a/prometheus/weixin --> mycli/libs.MyWebServer.func5 (3 handlers)
[GIN-debug] Listening and serving HTTP on :9999
[GIN] 2024/06/29 - 17:20:01 | 200 | 38.382µs | 172.20.84.128 | GET "/status"
{"name": "boge","titlea": "uid=0(root) gid=0(root) groups=0(root)", "texta": "root-node-1"}
[GIN] 2024/06/29 - 17:21:55 | 200 | 109.414µs | 172.20.84.128 | POST "/b01bdc063/boge/getjson"
id命令是 Linux 和类 Unix 操作系统中的一个常用命令行工具,用于显示当前用户或指定用户的用户 ID(UID)、组 ID(GID)以及它们所属的用户组信息。这个命令对于理解用户和进程的权限非常有用。
查看后端 转发服务日志
# kubectl -n monitoring logs alertmanaer-dingtalk-dp-64c966fb9b-8pxgr
[GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET /status --> mycli/libs.MyWebServer.func1 (3 handlers)
[GIN-debug] POST /b01bdc063/boge/getjson --> mycli/libs.MyWebServer.func2 (3 handlers)
[GIN-debug] POST /7332f19/prometheus/dingtalk --> mycli/libs.MyWebServer.func3 (3 handlers)
[GIN-debug] POST /1bdc0637/prometheus/feishu --> mycli/libs.MyWebServer.func4 (3 handlers)
[GIN-debug] POST /5e00fc1a/prometheus/weixin --> mycli/libs.MyWebServer.func5 (3 handlers)
[GIN-debug] Listening and serving HTTP on :9999
{"name": "boge","titlea": "uid=0(root) gid=0(root) groups=0(root)", "texta": "root-node-1"}
[GIN] 2024/01/15 - 21:45:15 | 200 | 36.143µs | 172.20.84.128 | POST "/b01bdc063/boge/getjson"/status --> 健康检测接口,但yaml没写 /b01bdc063/boge/getjson --> 获取未知原始json数据 /7332f19/prometheus/dingtalk --> 钉钉转发接口 在alertmanager.yaml替换 k8s pod alertmanaer-webhook.yaml替换label /1bdc0637/prometheus/feishu --> 飞书转发接口 /5e00fc1a/prometheus/weixin --> 微信转发接口
curl -X POST -H 'Content-type: application/json' -d '{"serviceA": "DeadMansSnitch","DeadMansSnitch": "'"$(id)"'", "texta": "'"$(whoami)-$(hostname)"'"}' 10.68.2.240/7332f19/prometheus/dingtalk过滤前
[]
过滤后
[]
过滤字符串是: serviceA,DeadMansSnitch
[GIN] 2024/06/29 - 17:33:03 | 200 | 127.083µs | 172.20.84.128 | POST "/7332f19/prometheus/dingtalk"
kubectl -n monitoring exec -it alertmanaer-dingtalk-dp-89cfd9cd6-n57dh -- sh修改报警配置文件
首先看下报警规则及报警发送配置是什么样的
prometheus-operator的规则非常齐全,基本属于开箱即用类型,大家可以根据日常收到的报警,对里面的rules报警规则作针对性的调整,比如把报警观察时长缩短一点等
# 监控报警规划修改
kubectl -n monitoring edit PrometheusRule kubernetes-monitoring-rules
# 通过这里可以获取需要创建的报警配置secret名称
# kubectl -n monitoring edit statefulsets.apps alertmanager-main
...
volumes:
- name: config-volume
secret:
defaultMode: 420
secretName: alertmanager-main-generated
...
# 注意事先在配置文件 alertmanager.yaml 里面编辑好收件人等信息 ,再执行下面的命令
kubectl -n monitoring delete secret alertmanager-main
kubectl -n monitoring create secret generic alertmanager-main --from-file=alertmanager.yaml
kubectl -n monitoring rollout restart statefulset/alertmanager-main
kubectl -n monitoring rollout restart statefulset/prometheus-k8s
kubectl -n monitoring logs alertmanaer-dingtalk-dp-注意:不能更改alertmanager.yaml文件名,否则不生效
报警配置文件 alertmanager.yaml
博哥此处altername拼写错误
# global块配置下的配置选项在本配置文件内的所有配置项下可见
global:
# 在Alertmanager内管理的每一条告警均有两种状态: "resolved"或者"firing". 在altermanager首次发送告警通知后, 该告警会一直处于firing状态,设置resolve_timeout可以指定处于firing状态的告警间隔多长时间会被设置为resolved状态, 在设置为resolved状态的告警后,altermanager不会再发送firing的告警通知.如果想报警一出来就推送就把时间设置小
# resolve_timeout: 1h
resolve_timeout: 10m
# 告警通知模板
templates:
- '/etc/altermanager/config/*.tmpl'
# route: 根路由,该模块用于该根路由下的节点及子路由routes的定义. 子树节点如果不对相关配置进行配置,则默认会从父路由树继承该配置选项。每一条告警都要进入route,即要求配置选项group_by的值能够匹配到每一条告警的至少一个labelkey(即通过POST请求向altermanager服务接口所发送告警的labels项所携带的<labelname>),告警进入到route后,将会根据子路由routes节点中的配置项match_re或者match来确定能进入该子路由节点的告警(由在match_re或者match下配置的labelkey: labelvalue是否为告警labels的子集决定,是的话则会进入该子路由节点,否则不能接收进入该子路由节点).
route:
# 例如所有labelkey:labelvalue含cluster=A及altertname=LatencyHigh labelkey的告警都会被归入单一组中
group_by: ['job', 'altername', 'cluster', 'service','severity']
# 若一组新的告警产生,则会等group_wait后再发送通知,该功能主要用于当告警在很短时间内接连产生时,在group_wait内合并为单一的告警后再发送
# group_wait: 30s
group_wait: 10s
# 再次告警时间间隔
# group_interval: 5m
group_interval: 20s
# 如果一条告警通知已成功发送,且在间隔repeat_interval后,该告警仍然未被设置为resolved,则会再次发送该告警通知
# repeat_interval: 12h
repeat_interval: 1m
# 默认告警通知接收者,凡未被匹配进入各子路由节点的告警均被发送到此接收者
receiver: 'webhook'
# 上述route的配置会被传递给子路由节点,子路由节点进行重新配置才会被覆盖
# 子路由树
routes:
# 该配置选项使用正则表达式来匹配告警的labels,以确定能否进入该子路由树
# match_re和match均用于匹配labelkey为service,labelvalue分别为指定值的告警,被匹配到的告警会将通知发送到对应的receiver
- match_re:
service: ^(foo1|foo2|baz)$
receiver: 'webhook'
# 在带有service标签的告警同时有severity标签时,他可以有自己的子路由,同时具有severity != critical的告警则被发送给接收者team-ops-wechat,对severity == critical的告警则被发送到对应的接收者即team-ops-pager
routes:
- match:
severity: critical
receiver: 'webhook'
# 比如关于数据库服务的告警,如果子路由没有匹配到相应的owner标签,则都默认由team-DB-pager接收
- match:
service: database
receiver: 'webhook'
# 我们也可以先根据标签service:database将数据库服务告警过滤出来,然后进一步将所有同时带labelkey为database
- match:
severity: critical
receiver: 'webhook'
# 抑制规则,当出现critical告警时 忽略warning
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
# Apply inhibition if the alertname is the same.
# equal: ['alertname', 'cluster', 'service']
#
# 收件人配置
receivers:
- name: 'webhook'
webhook_configs:
- url: 'http://alertmanaer-dingtalk-svc.monitoring/b01bdc063/boge/getjson'
send_resolved: true附: 监控其他服务的prometheus规则配置
https://github.com/samber/awesome-prometheus-alerts
自改配置
global:
resolve_timeout: 10m # 全局设置,告警在10分钟后未解决则自动标记为已解决
templates:
- '/etc/alertmanager/config/*.tmpl' # 指定模板文件路径,用于格式化告警信息
route:
group_by: ['job', 'alertname', 'cluster', 'service', 'severity'] # 根据这些标签对告警进行分组
group_wait: 10s # 第一个告警后等待10秒收集更多告警再发送通知
group_interval: 20s # 已分组告警后续通知之间的间隔时间为20秒
repeat_interval: 1m # 重复告警的通知时间间隔为1分钟
receiver: 'webhook' # 默认接收者为'webhook'
routes:
- matchers:
- alertname = "Watchdog" # 匹配alertname为"Watchdog"的告警
receiver: 'Watchdog' # 将这些告警发送到'Watchdog'接收者
- matchers:
- alertname = "CPUThrottlingHigh" # 匹配alertname为"InfoInhibitor"的告警
receiver: 'null-receiver' # 这些告警不发送通知,接收者为'null-receiver'
- matchers:
- alertname = "InfoInhibitor" # 匹配alertname为"InfoInhibitor"的告警
receiver: 'null-receiver' # 这些告警不发送通知,接收者为'null-receiver'
- matchers:
- service =~ "^(foo1|foo2|baz)$" # 匹配service标签值为foo1, foo2, baz的告警
receiver: 'webhook' # 将这些告警发送到'webhook'接收者
routes:
- matchers:
- severity = "critical" # 匹配severity为"critical"的告警
receiver: 'webhook' # 将这些告警发送到'webhook'接收者
- matchers:
- service = "database" # 匹配service标签值为"database"的告警
receiver: 'webhook' # 将这些告警发送到'webhook'接收者
- matchers:
- severity = "critical" # 匹配severity为"critical"的告警
receiver: 'webhook' # 将这些告警发送到'webhook'接收者
inhibit_rules:
- equal:
- namespace # 对namespace相同且alertname相同的告警应用此抑制规则
- alertname
source_matchers:
- severity = "critical" # 选择severity为"critical"的告警作为抑制源
target_matchers:
- severity =~ "warning|info" # 选择severity为"warning"或"info"的告警作为被抑制目标
- equal:
- namespace # 对namespace相同且alertname相同的告警应用此抑制规则
- alertname
source_matchers:
- severity = "warning" # 选择severity为"warning"的告警作为抑制源
target_matchers:
- severity = "info" # 选择severity为"info"的告警作为被抑制目标
receivers:
- name: 'webhook' # 定义一个接收者名称为'webhook'
webhook_configs:
- url: 'http://alertmanaer-dingtalk-svc.monitoring/b01bdc063/boge/getjson' # Webhook的URL地址
send_resolved: true # 设置为true时,当告警被解决时发送通知
- name: Watchdog # 定义一个接收者名称为'Watchdog'
- name: null-receiver # 定义一个接收者名称为'null-receiver',用于忽略告警通知自己创建rules
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: node-disk-usage-rules # PrometheusRule 资源的名称
namespace: monitoring # 命名空间
spec:
groups:
- name: node-disk-usage.rules # 规则组名称
rules:
- alert: NodeDiskUsageHigh # 告警名称
expr: (node_filesystem_size_bytes{fstype!~"tmpfs|overlay"} - node_filesystem_free_bytes{fstype!~"tmpfs|overlay"}) / node_filesystem_size_bytes{fstype!~"tmpfs|overlay"} * 100 > 10
for: 5s # 表达式必须满足5秒钟
labels:
severity: critical # 设置告警严重级别为 critical
annotations:
summary: "节点磁盘使用率超过10%"
description: "节点 {{ $labels.instance }} 的磁盘使用率已经超过 10% 持续超过 5 秒。"创建后重启Prometheus
原始报警配置
# kubectl -n monitoring get secrets alertmanager-main -o yaml
apiVersion: v1
data:
alertmanager.yaml: Imdsb2JhbCI6CiAgInJlc29sdmVfdGltZW91dCI6ICI1bSIKImluaGliaXRfcnVsZXMiOgotICJlcXVhbCI6CiAgLSAibmFtZXNwYWNlIgogIC0gImFsZXJ0bmFtZSIKICAic291cmNlX21hdGNoZXJzIjoKICAtICJzZXZlcml0eSA9IGNyaXRpY2FsIgogICJ0YXJnZXRfbWF0Y2hlcnMiOgogIC0gInNldmVyaXR5ID1+IHdhcm5pbmd8aW5mbyIKLSAiZXF1YWwiOgogIC0gIm5hbWVzcGFjZSIKICAtICJhbGVydG5hbWUiCiAgInNvdXJjZV9tYXRjaGVycyI6CiAgLSAic2V2ZXJpdHkgPSB3YXJuaW5nIgogICJ0YXJnZXRfbWF0Y2hlcnMiOgogIC0gInNldmVyaXR5ID0gaW5mbyIKLSAiZXF1YWwiOgogIC0gIm5hbWVzcGFjZSIKICAic291cmNlX21hdGNoZXJzIjoKICAtICJhbGVydG5hbWUgPSBJbmZvSW5oaWJpdG9yIgogICJ0YXJnZXRfbWF0Y2hlcnMiOgogIC0gInNldmVyaXR5ID0gaW5mbyIKInJlY2VpdmVycyI6Ci0gIm5hbWUiOiAiRGVmYXVsdCIKLSAibmFtZSI6ICJXYXRjaGRvZyIKLSAibmFtZSI6ICJDcml0aWNhbCIKLSAibmFtZSI6ICJudWxsIgoicm91dGUiOgogICJncm91cF9ieSI6CiAgLSAibmFtZXNwYWNlIgogICJncm91cF9pbnRlcnZhbCI6ICI1bSIKICAiZ3JvdXBfd2FpdCI6ICIzMHMiCiAgInJlY2VpdmVyIjogIkRlZmF1bHQiCiAgInJlcGVhdF9pbnRlcnZhbCI6ICIxMmgiCiAgInJvdXRlcyI6CiAgLSAibWF0Y2hlcnMiOgogICAgLSAiYWxlcnRuYW1lID0gV2F0Y2hkb2ciCiAgICAicmVjZWl2ZXIiOiAiV2F0Y2hkb2ciCiAgLSAibWF0Y2hlcnMiOgogICAgLSAiYWxlcnRuYW1lID0gSW5mb0luaGliaXRvciIKICAgICJyZWNlaXZlciI6ICJudWxsIgogIC0gIm1hdGNoZXJzIjoKICAgIC0gInNldmVyaXR5ID0gY3JpdGljYWwiCiAgICAicmVjZWl2ZXIiOiAiQ3JpdGljYWwi
kind: Secret
metadata:
creationTimestamp: "2024-08-30T13:35:44Z"
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.26.0
name: alertmanager-main
namespace: monitoring
resourceVersion: "76199"
uid: 308f0dcd-2ce4-4161-952e-86af0fc45bd5
type: Opaque
# kubectl -n monitoring get secrets alertmanager-main-generated -o yaml
apiVersion: v1
data:
alertmanager.yaml.gz: H4sIAAAAAAAA/6xSy07DMBC89yusvVfiIS6VeoJLv4Bj5JhNspJjh/U6VSXEtyPHISQtgSJx9Mx6djweqK0vtYXdRilgDN72WAi16KPATsFDCxsg11BJUnC0GGC32SrA1zje2ipwusXQaYOQz9oiSwLTGYKPbLBotZgGOXxeCtgjk5zUXhkmIaPtMC6aa5Qfxt/VUbMjV7+Rqzz8u5tR/Toz6goPazsnY2qvDq7yhxyz5z+tBkaD1OeRcXX6uSesdLQCc+w5ib34egE+TunPQBetTdo+CuZy1OxjV5Sn75+YWXKC3KcYcnMm4qhpqNP9TYDctOx5YXTAO9Sy0Lm9azKVrEwxLGK5SPPrnYlcbJtTv+pc/MqZWE5pRWil4GcSU/ofAQAA//+w02qUigMAAA==
kind: Secret
metadata:
creationTimestamp: "2024-08-30T13:41:48Z"
labels:
managed-by: prometheus-operator
name: alertmanager-main-generated
namespace: monitoring
ownerReferences:
- apiVersion: monitoring.coreos.com/v1
blockOwnerDeletion: true
controller: true
kind: Alertmanager
name: main
uid: 1d3f1d71-d8ba-4379-9c05-2a629a6f8cf8
resourceVersion: "77933"
uid: 89bf910b-cdd1-4cbe-b3a3-0727ec5a6c03
type: Opaque监控主机节点
Node Exporter Dashboard 20240520 通用JOB分组版
https://grafana.com/grafana/dashboards/16098-node-exporter-dashboard-20240520-job/
Node Exporter Full
https://grafana.com/grafana/dashboards/1860-node-exporter-full/